Java Colleections
Exception
Section titled “Exception”十三、常用类
Section titled “十三、常用类”Wrapper
Section titled “Wrapper”Java 有 8 种基本数据类型:整型(byte、short、int、long)、浮点型(float、double)、布尔型 boolean、字符型 char,相对应地,Java 提供了 8 种包装类 Byte、Short、Integer、Long、Float、Double、Boolean、Character 包装类创建对象的方式就跟其他类一样。
Integer num = new Integer(0);基本数据类型转换
Section titled “基本数据类型转换”装箱:基本数据类型 ->对象 拆箱:对象->基本数据类型
//手动装箱int n1 = 100;Integer integer = new Integer(n1);Integer integer1 = Integer.valueOf(n1);//手动拆箱int i = integer.intValue();//JDK5之前需要手动装箱拆箱//自动装箱int n2 = 100;Integer integer2 = n2;Double d = 100d;Float f = 1.5f;//自动拆箱int n3 = ingeger2;
//TestObject obj = true ? new Integer(1) : new Double(2.0);System.out.println(obj);[OUTPUT] 1.0这是因为Java中的三元运算符要求两个操作数具有相同的类型,否则需要进行类型转换。在这个例子中,Integer和Double是不同的类型,因此编译器会将它们都转换为更通用的类型,即Number类型。而由于三元运算符的返回值类型是Object类型,所以编译器最终将Number类型的结果转换为Object类型。因此,Object obj的值是1.0,即将Integer类型的1转换为Double类型的1.0。Wrapper 常用方法
Section titled “Wrapper 常用方法”Java 中的包装类是基本数据类型对应的类,它们提供了许多有用的方法来操作基本数据类型。下面是一些常用的包装类方法:
-
intValue()、longValue()、floatValue()、doubleValue(): 这些方法可以将包装类对象转换为对应的基本数据类型。例如,Integer 对象调用 intValue()方法可以返回 int 类型的值。
-
parseXXX(String s):这些方法可以将字符串解析为对应的基本数据类型。例如,Integer.parseInt(“123”)可以返回 int 类型的 123。
-
valueOf():这个方法可以将基本数据类型转换为对应的包装类对象。例如,Integer.valueOf(123)可以返回一个 Integer 对象。
-
compareTo():这个方法可以比较两个包装类对象的大小。例如,Integer 对象调用 compareTo()方法可以和另一个 Integer 对象进行比较。
-
equals():这个方法可以比较两个包装类对象是否相等。例如,Integer 对象调用 equals()方法可以和另一个 Integer 对象进行比较。
-
toString():这个方法可以将包装类对象转换为字符串。例如,Integer 对象调用 toString()方法可以返回一个表示该对象值的字符串。
-
Character 类常用方法
Character.isDight('a');Character.isLetter('a');Character.isLowerCase('a');Character.isUpperCase('a');Character.isWhitespace('a');Character.toLowerCase('a');Character.toUpperCase('a');
Integer
Section titled “Integer”在 Java 中,当我们使用 Integer 等包装类来表示一个数字时,会根据具体情况创建对象或直接使用缓存的对象。具体来说,如果数字在-128 到 127 之间,就会直接使用缓存的对象,而不会创建新的对象。这是因为 Java 会预先创建这些数字对应的对象,并将它们缓存起来,以提高性能和节省内存。这个缓存范围可以通过 Java 虚拟机参数 -XX:AutoBoxCacheMax=size来调整,其中 size 是缓存的最大值。如果数字超出了缓存范围,就会创建新的对象来表示它。
只要有基本数据类型,判断的是值是否相等
Integer m = 1;Integer n = 1;m == n; //trueInteger i1 = new Integer(1);Integer i2 = new Integer(2);i1 == i1; //false//只要有基本数据类型,判断的是值是否相等Integer i1 = 129;int i2 = 129;i1 == i2; //trueString
Section titled “String”
Serializable:表示 String 对象可以实现串行化,意味着 String 对象可以在网络传输
Comparable:表示 String 对象可以相互比较大小
CharSequence:字符序列
-
String 是 final 类,不能被继承
String 类中的 value[]数组是 final 的,这意味着一旦字符串被创建,它的值就不能被修改。这种限制确保了字符串对象的不可变性,这也是 String 类的一个重要特性。由于字符串是不可变的,因此可以更安全地在多个线程之间共享,而不必担心并发修改问题。此外,字符串的不可变性还使得它们可以用作 Map 中的键或 Set 中的元素,因为它们的哈希值不会改变
public final class Stringimplements java.io.Serializable, Comparable<String>, CharSequence {/** The value is used for character storage. */private final char value[];......}char[] v2 = {a,c};value = v2; //error,value地址不可修改value[2] = 'h'; //ok -
字符串常量对象是用双引号括起的字符序列。例如:“你好”、“12.97”、“boy”等
-
字符串的字符使用 Unicode 字符编码,一个字符(不区分字母还是汉字)占两个字节
-
String 类较常用
constructor- String s1 = new String();
- Strings2 = new String(String original);
- Strings3 = new String(char[] a);
- String s4 = new String(char[] a,int startlndex,int count)
两种创建 String 对象的区别
-
方式一直接赋值
String test ="ab”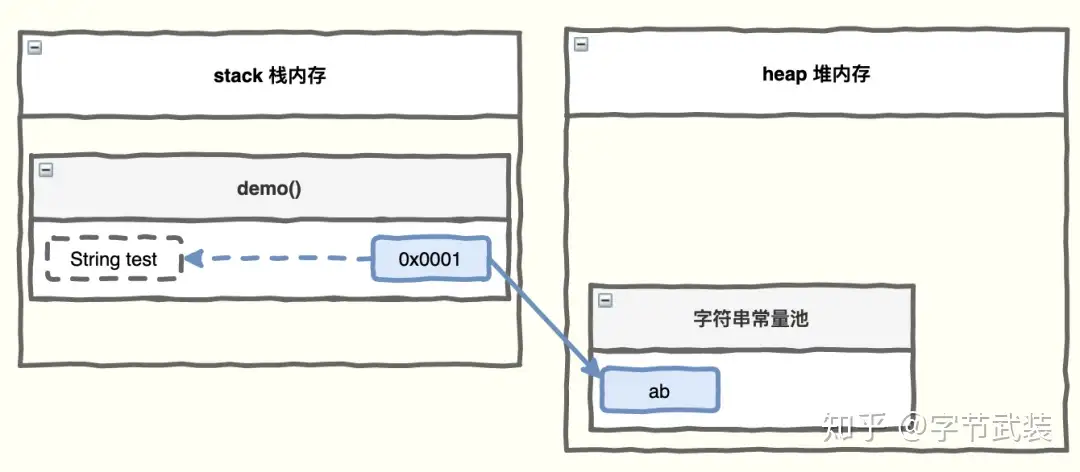
方式二:调用构造器
String test = new String("ab");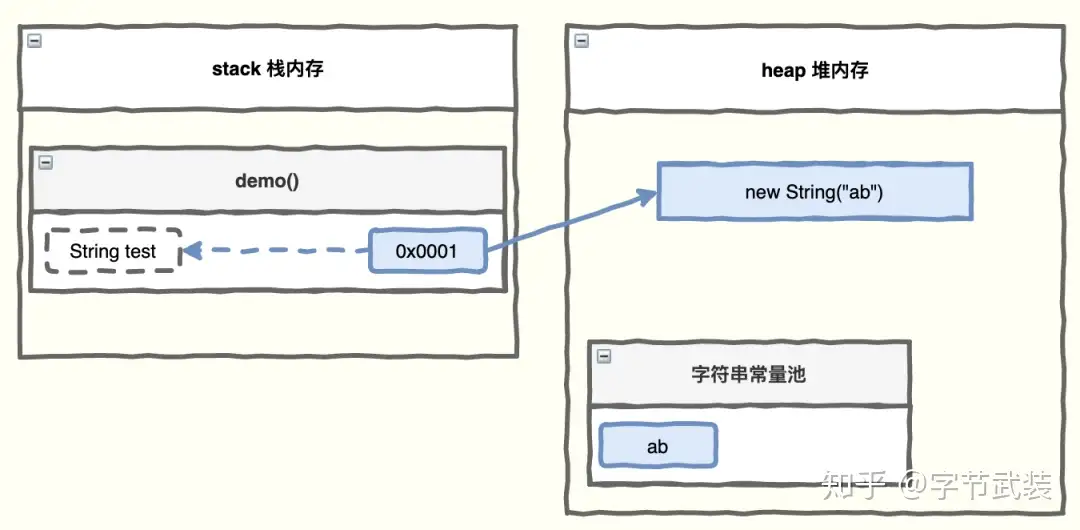
-
方式一: 先从常量池查看是否有”abc”数据空间,如果有,直接指向;如果没有则重新创建,然后指向;s 最终指向的是常量池的空间地址 方式二:先在堆中创建空间,里面维护了 value 属性,指向常量池的 abc 空间如果常量池没有”abc”,重新创建,如果有,直接通过 value 指向。最终指向的是堆中的空间地址
String a = "acc";String b = "acc";a.equals(b); //true,equals()比较字符串内容a == b; //true,==比较引用类型时看内存地址
String a = "acc";String b = new String("acc");a.equals(b); //Ta == b; //F
String s1 = "a";String s2 = "b";String s3 = "a";String s4 = new String("a");s1 == s2; //Fs1 == s3; //Ts1 == s4; //Fs1.equals(s4); //T
Person p1 = new Person();p1.name = "a";Person p2 = new Person();p2.name = "a";p1.name.equals(p2.name); //Truep1.name = p2.name;//True; p1,p2分别指向堆中的name,p1.name指向常量池的a,p2.name也指向该ap1.name == "a"; //TrueString 特性
Section titled “String 特性”String s1 = "aa";s1 = "ddd";在这个例子中,创建了两个字符串对象。第一个字符串对象”aa”被分配给了 s1 变量,第二个字符串对象”ddd”被分配给了 s2 变量。由于字符串是不可变的,因此每次对字符串执行更改操作时,都会创建一个新的字符串对象来代表新的字符串值。所以在这个例子中,我们创建了两个不同的字符串对象。
String s = "ab" + "cd";//底层优化为String s = "abcd";在这个例子中,只创建了一个字符串对象。当 Java 编译器在编译时遇到字符串字面量时,它会将它们连接在一起,形成一个单独的字符串常量。因此,在这个例子中,“ab”和”cd”被连接成一个新的字符串”abcd”,并且只创建了一个字符串对象来代表它。当然,如果你在代码中使用了多个字符串变量或字符串拼接操作,那么就会创建多个字符串对象。
String str1 = "hello";String str2 = "world";String str = str1 + str2;//底层实现StringBuilder sb = new StringBuilder();sb.append(str1);sb.append(str2);String str = sb.toString();//str1,str2分别指向池中的hello,world//str指向堆中的value,value指向"hello,world"当调用 intern()时,如果池中已经包含一个等于(是否相等用 equals(obj)确定)此 String 对象的字符串时,则返回池中的字符串;否则,则将该字符串添加到池中,并返回此 String 对象的引用
解读:str.intern()最终返回的是常量池的地址
String str = "abc";String str1 = new String("abc");str == str1.intern(); //T,都指向常量池str1 == str1.intern(); //F,str1指向堆,堆中的value[]指向常量池,str1.intern()返回值指向常量池
String s1 = "hello";String s2 = "world";String s3 = "helloworld";s3 == (s1 + s2).intern(); //True这段代码的输出是”hsp and hava”。
在 change()方法中,我们首先将 str 参数设置为”java”,但是由于 Java 中的字符串是不可变的,所以这个操作不会改变原始的字符串对象。然后,我们将 ch 数组的第一个元素从’j’改为’h’。
在 main()方法中,我们创建了 Main 类的一个实例 ex,并将其 str 和 ch 字段传递给 change()方法。由于 Java 中的参数传递是按值传递的,因此实际上是将 str 和 ch 的副本传递给了 change()方法。在 change()方法中,我们修改了 ch 数组的第一个元素,这也修改了 Main 类中的 ch 数组。因此,当我们在 main()方法中打印 ch 数组时,它的值已经被改变了。
但是,在 change()方法中修改 str 参数并不会影响 Main 类中的 str 字段,因为 Java 中的字符串是不可变的。因此,在 main()方法中打印 ex.str 时,它的值仍然是”hsp”。
下面是内存分析图:
+--------+ +-----------------+| main | | ex |+--------+ +-----------------+| args | | str: "hsp" || ex | | ch: {'h', 'a', |+--------+ | 'v', 'a'} | +-----------------+在这个示例中,我们有一个名为 main 的方法和一个名为 ex 的 Main 类实例。ex 实例有一个名为 str 的字符串字段和一个名为 ch 的字符数组字段。在执行 change()方法时,我们传递了 ex.str 和 ex.ch 的副本。在 change()方法中,我们修改了 ch 数组的第一个元素,但是 str 参数被重新分配了一个新的字符串值,并不会影响 Main 类中的 str 字段。
public class Main { String str = new String("hsp"); final char[] ch = { 'j', 'a', 'v', 'a' };
public void change(String str, char ch[]){ str = "java"; ch[0] = 'h'; }
public static void main(String[] args) { Main ex = new Main(); ex.change(ex.str, ex.ch); System.out.print(ex.str + " and "); System.out.println(ex.ch); }}[OUTPUT] hsp and havaString Method
Section titled “String Method”-
equals// 区分大小写,判断内容是否相等 -
equalslgnoreCase//忽略大小写的判断内容是否相等 -
length// 获取字符的个数,字符串的长度 -
indexof//获取字符在字符串中第 1 次出现的索引,索引从 0 开始,如果找不到,返回-1 -
lastIndexof//获取字符在字符串中最后 1 次出现的索引,索引从 0 开始,如找不到,返回-1 -
substring//截取指定范围的子串str1.substring(2,5)//从索引 2 开始,截取到索引 4 -
trim//去前除后空格 -
charAt//获取某索引处的字符,注意不能使用 Str[index] 这种方式 -
toUpperCase(),toLowerCase()//转大小写 -
concat//拼接String s = "Hello";s.concat(",").concat("World!"); -
replace//替换String s1 = s.replace("abc","z"); //将s中的abc替换为z,s的值不受影响 -
split//分割String poem = "锄禾日当午,汗滴禾下土,谁知盘中餐,粒粒皆辛苦";String[] split = poem.split(","); -
toCharArray//转换成字符数组char[] s = poem.toCharArray(); -
s1.compareTo(s2)//比较两个字符串的大小-
长度不相等,返回 s1 长度 - s2 长度;
-
长度相等,逐个字符比较,当两个字符不相等时,返回其差值
String a = "jcck";String b = "jack";a.compareTo(b); //返回值为'c' - 'a' 即2
-
-
String.format()String formatStr = "My name is %s Age is %d Grade is %.2f";String info = String.format(formatStr,name,age,score);占位符(placeholder),通常用于格式化字符串,它可以在字符串中预留位置,以便在运行时动态填充具体的值。在 Java 中,占位符通常使用”%s”表示字符串类型,“%d”表示整数类型,“%f”表示浮点数类型,“%t”表示日期时间类型、“%b”表示布尔类型等。
使用占位符可以使代码更加简洁、易读,并且可以避免一些潜在的错误。例如,在拼接 SQL 语句时,如果直接将参数值拼接到字符串中,可能会导致 SQL 注入等安全问题。而使用占位符可以有效地避免这些问题。
在 Java 中,可以使用
String.format()方法来将占位符替换为具体的值,也可以使用System.out.printf()方法来格式化输出。除此之外,还有一些第三方库,例如 Apache Commons Lang 库中的StringUtils.format()方法,也可以用于格式化字符串。
StringBuffer
Section titled “StringBuffer”StringBuffer 类是 Java 中一个可变的字符串类,它与 String 类类似,但是可以进行修改操作而不需要创建新的字符串对象。StringBuffer 类中的方法可以用于在字符串中插入、删除、替换字符等操作,这些操作都是在原有的字符串上进行的,而不会创建新的字符串对象,因此可以提高程序的效率。
StringBuffer 类中的常用方法包括:
append():向字符串末尾添加新的字符或字符串。insert(5,"hello"):在索引 9 插入 hello,之后的字符往后移。delete():删除指定位置的字符或一段字符,str.delete(2,5)前闭后开删除索引 2-4。replace(9,11,"Hello,World"):用 Hello,World 替换索引 9-10。reverse():反转字符串中的字符顺序。
需要注意的是,由于 StringBuffer 类是可变的,因此在多线程环境中使用时需要进行同步处理,可以使用 synchronized 关键字来保证线程安全。另外,在 Java 5 之后,还引入了 StringBuilder 类,它与 StringBuffer 类类似但是不是线程安全的,因此在单线程环境中使用 StringBuilder 类可以提高程序的效率。
String VS StringBuffer
- String 保存的是字符串常量,里面的值不能更改,每次 String 类的更新实际上就是更改地址,效率较低 //private final char value[];
- StringBuffer 保存的是字符串变量,里面的值可以更改,每次 StringBuffer 的更新实际上可以更新内容,不用每次更新地址(value 数组空间不够时扩容,此时地址会更新),效率较高 //char[] value; 这个放在堆中
//String -> StringBufferString str = "hello";//使用构造器StringBuffer sb = StringBuffer(str);//appendsb1 = sb1.append(str);
//StringBuffer -> StringStringBuffer sb2 = new StringBuffer("hello");//toString()String s1 = sb2.toString();//ConstructorString s2 = new String(sb2);StringBuffer Constructor
Section titled “StringBuffer Constructor”StringBuffer 类有以下的构造方法:
StringBuffer():创建一个空的字符串缓冲区,其初始容量为 16 个字符。StringBuffer(int capacity):创建一个空的字符串缓冲区,其初始容量可容纳指定数量的字符。StringBuffer(String str):使用指定的字符串内容创建一个字符串缓冲区,其初始容量为 16 个字符加上字符串参数的长度。str.length() + 16
//数字整数部分每三位插入一个逗号 public static StringBuffer addCommasToInteger(String str) { if (str == null || str.isEmpty()) { throw new IllegalArgumentException("String must not be null"); }
int decimalIndex = str.indexOf("."); String integerPart = decimalIndex < 0 ? str : str.substring(0, decimalIndex); String decimalPart = decimalIndex < 0 ? "" : str.substring(decimalIndex);
StringBuffer result = new StringBuffer(integerPart); int length = integerPart.length();
for(int i = length - 3; i > 0; i -= 3) { result.insert(i, ","); }
return result.append(decimalPart); }StringBuilder
Section titled “StringBuilder”- 一个可变的字符序列。此类提供一个与 StringBuffer 兼容的 API,但不保证同步(StringBuilder 不是线程安全)。该类被设计用作 StringBuffer 的一个简易替换,用在字符串缓冲区被单个线程使用的时候。如果可能,建议优先采用该类因为在大多数实现中,它比 StringBuffer 要快 。
- 在 StringBuilder 上的主要操作是
append和insert方法,可重载这些方法以接受任意类型的数据
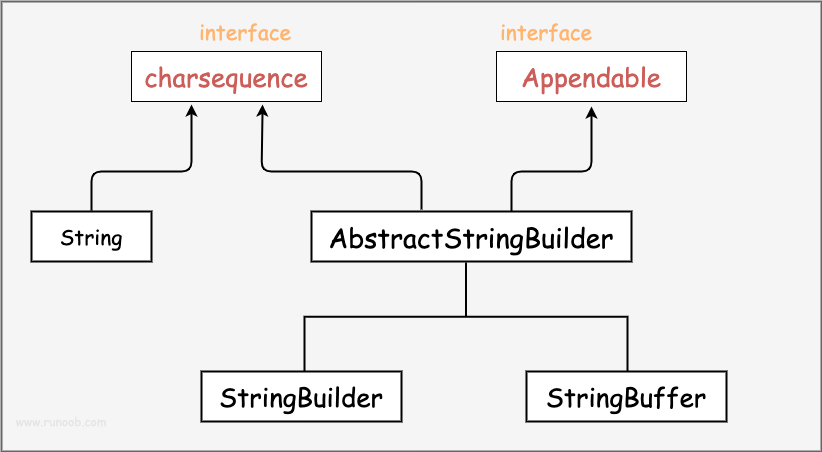
- String、StringBuffer 和 StringBuilder 的比较
- StringBuilder 和 StringBuffer 非常类似,均代表可变的字符序列,而且方法也一样
- String: 不可变字符序列, 效率低,但是复用率高
- StringBuffer: 可变字符序列、效率较高(增删)、线程安全
- StringBuilder: 可变字符序列、效率最高、线程不安全
- String 使用注意说明:
- string s=“a”;//创建了一个字符串 s +=“b”://实际上原来的”a”字符串对象已经丢弃, 现在又产生了一个字符串 s+“b”(也就是”ab”)。如果多次执行这些改变串内容的操作,会导致大量副本字符串对象存留在内存中,降低效率。如果这样的操作放到循环中,会极大影响程序的性能
- 结论: 如果我们对字符串做大量修改,不要使用 String
- 结论
- 如果字符串存在大量的修改操作,一般使用
StringBuffer或StringBuilder - 如果字符串存在大量的修改操作,并在单线程的情况,使用
StringBuilder - 如果字符串存在大量的修改操作,并在多线程的情况,使用
StringBuffer - 如果我们字符串很少修改,被多个对象引用,使用
String,比如配置信息等
- 如果字符串存在大量的修改操作,一般使用
Method
Section titled “Method”abs():返回一个数的绝对值。ceil():返回一个大于或等于参数的最小 double 值,该值等于某个整数,即向上取整。floor():返回一个小于或等于参数的最大 double 值,该值等于某个整数,即向下取整。max():返回两个参数中较大的那个。min():返回两个参数中较小的那个。pow():返回第一个参数的第二个参数次方。random():返回一个介于 0.0 和 1.0 之间的随机数(不包括 1.0)。round():返回最接近参数的 int 值,四舍五入。
int number1 = -5;int number2 = 10;
// 使用 abs() 方法获取 number1 的绝对值int absNumber1 = Math.abs(number1);System.out.println("number1 的绝对值为:" + absNumber1);
// 使用 ceil() 方法获取 number2 的上限整数double ceilNumber2 = Math.ceil(number2);System.out.println("number2 的上限整数为:" + ceilNumber2);
// 使用 floor() 方法获取 number1 的下限整数double floorNumber1 = Math.floor(number1);System.out.println("number1 的下限整数为:" + floorNumber1);
// 使用 max() 方法获取 number1 和 number2 中的较大值int maxNumber = Math.max(number1, number2);System.out.println("number1 和 number2 中的较大值为:" + maxNumber);
// 使用 min() 方法获取 number1 和 number2 中的较小值int minNumber = Math.min(number1, number2);System.out.println("number1 和 number2 中的较小值为:" + minNumber);
// 使用 pow() 方法获取 number1 的 3 次方double powNumber1 = Math.pow(number1, 3);System.out.println("number1 的 3 次方为:" + powNumber1);
// 使用 random() 方法获取一个介于 0.0 和 1.0 之间的随机数double randomNumber = Math.random();System.out.println("随机数为:" + randomNumber);
// 使用 round() 方法获取 3.6 的四舍五入整数int roundNumber = Math.round(3.6f);System.out.println("3.6 的四舍五入整数为:" + roundNumber);在 Java 中,生成一个介于 a 和 b 之间的随机数有多种实现方式。以下是三种常见的方式:
- 使用
Math.random()方法:
int randomNum = (int) (Math.random() * (b - a + 1)) + a;//(int)强转为截断小数点后面的,即为向下取整- Recomended使用
java.util.Random类:
import java.util.Random;
Random random = new Random();int randomNum = random.nextInt(b - a + 1) + a;- 使用
ThreadLocalRandom类(Java 7 及以上版本):
import java.util.concurrent.ThreadLocalRandom;
int randomNum = ThreadLocalRandom.current().nextInt(a, b + 1);请注意,上述代码中的变量 a和 b分别表示范围的下限和上限。这些代码将生成一个在闭区间[a, b]内的随机整数。
BigInteger
Section titled “BigInteger”import java.math.BigInteger;import java.util.Scanner;
public class Test09 { public static void main(String[] args) { Scanner input = new Scanner(System.in); System.out.println("请输入一个整型数字:"); // 保存用户输入的数字 int num = input.nextInt();
// 使用输入的数字创建BigInteger对象 BigInteger bi = new BigInteger(num + "");
// 计算大数字加上99的结果 System.out.println("加法操作结果:" + bi.add(new BigInteger("99")));
// 计算大数字减去25的结果 System.out.println("减法操作结果:" + bi.subtract(new BigInteger("25")));
// 计算大数字乘以3的结果 System.out.println("乘法橾作结果:" + bi.multiply(new BigInteger("3")));
// 计算大数字除以2的结果 System.out.println("除法操作结果:" + bi.divide(new BigInteger("2")));
// 计算大数字除以3的商 System.out.println("取商操作结果:" + bi.divideAndRemainder(new BigInteger("3"))[0]);
// 计算大数字除以3的余数 System.out.println("取余操作结果:" + bi.divideAndRemainder(new BigInteger("3"))[1]);
// 计算大数字的2次方 System.out.println("取 2 次方操作结果:" + bi.pow(2));
// 计算大数字的相反数 System.out.println("取相反数操作结果:" + bi.negate()); }}BigDecimal
Section titled “BigDecimal”-
BigDecimal(int)
创建一个具有参数所指定整数值的对象
-
BigDecimal(double)
创建一个具有参数所指定双精度值的对象
-
BigDecimal(long)
创建一个具有参数所指定长整数值的对象
-
推荐使用的构造器 BigDecimal(String)
创建一个具有参数所指定以字符串表示的数值的对象
double x = 1.1;BigDecimal xx = new BigDecimal(Double.toString(x));原因分析:
- 参数类型为 double 的构造方法的结果有一定的不可预知性。有人可能认为在 Java 中写入 newBigDecimal(0.1)所创建的 BigDecimal 正好等于 0.1(非标度值 1,其标度为 1),但是它实际上等于 0.1000000000000000055511151231257827021181583404541015625。这是因为 0.1 无法准确地表示为 double(或者说对于该情况,不能表示为任何有限长度的二进制小数)。这样,传入到构造方法的值不会正好等于 0.1(虽然表面上等于该值)。
- String 构造方法是完全可预知的:写入 newBigDecimal(“0.1”) 将创建一个 BigDecimal,它正好等于预期的 0.1。因此,比较而言, 通常建议优先使用 String 构造方法。
- 当 double 必须用作 BigDecimal 的源时,请注意,此构造方法提供了一个准确转换;它不提供与以下操作相同的结果:先使用 Double.toString(double)方法,然后使用 BigDecimal(String)构造方法,将 double 转换为 String。要获取该结果,请使用 static valueOf(double)方法
Method
Section titled “Method”-
add(BigDecimal)
BigDecimal 对象中的值相加,返回 BigDecimal 对象
-
subtract(BigDecimal)
BigDecimal 对象中的值相减,返回 BigDecimal 对象
-
multiply(BigDecimal)
BigDecimal 对象中的值相乘,返回 BigDecimal 对象
-
divide(BigDecimal) BigDecimal 对象中的值相除,返回 BigDecimal 对象
通过 BigDecimal 的 divide 方法进行除法时当不整除,出现无限循环小数时,就会抛异常:
java.lang.ArithmeticException: Non-terminating decimal expansion; no exact representable decimal result.解决方法:
divide 方法设置精确的小数点,如:divide(xxxxx,2)
-
toString()
将 BigDecimal 对象中的值转换成字符串
-
doubleValue()
将 BigDecimal 对象中的值转换成双精度数
-
floatValue()
将 BigDecimal 对象中的值转换成单精度数
-
longValue()
将 BigDecimal 对象中的值转换成长整数
-
intValue()
将 BigDecimal 对象中的值转换成整数
Arrays
Section titled “Arrays”ArraysMethod
Section titled “ArraysMethod”java.util.Arrays是 Java 中用于操作数组的类,提供了许多有用的方法来处理数组。以下是一些常用的方法:
-
sort():对数组进行排序,可以按升序或降序排列。 -
binarySearch():在有序数组中搜索指定元素,返回元素的索引,未找到则返回-(low + 1);。// Like public version, but without range checks.private static int binarySearch(int[] a, int fromIndex, int toIndex,int key) {int low = fromIndex;int high = toIndex - 1;while (low <= high) {int mid = (low + high) >>> 1;int midVal = a[mid];if (midVal < key)low = mid + 1;else if (midVal > key)high = mid - 1;elsereturn mid; // key found}return -(low + 1); // key not found.} -
equals():比较两个数组是否相等,如果两个数组具有相同的长度并且包含相同的元素,则返回 true。 -
fill():将数组的所有元素设置为指定的值。 -
copyOf():复制一个数组,可以指定新数组的长度。Integer[] newArr = Arrays.copyOf(arr,5);- 从 arr 数组中,拷贝
arr.Length()个元素到 newArr 数组中 - 如果拷贝的长度大于
arr.length()就在新数组的后面 增加null - 如果拷贝长度 < 0 就抛出异常
NegativeArraySizeException
-
toString():将数组转换为字符串形式。
下面是一些使用这些方法的示例代码:
// 使用 sort() 方法对整型数组进行升序排列int[] numbers = {5, 3, 8, 4, 2};Arrays.sort(numbers);System.out.println(Arrays.toString(numbers));
// 使用 binarySearch() 方法在已排序的整型数组中查找指定元素int[] sortedNumbers = {2, 3, 4, 5, 8};int index = Arrays.binarySearch(sortedNumbers, 4);System.out.println("元素 4 在数组中的索引为:" + index);
// 使用 equals() 方法比较两个整型数组是否相等int[] array1 = {1, 2, 3};int[] array2 = {1, 2, 3};boolean isEqual = Arrays.equals(array1, array2);System.out.println("两个数组是否相等:" + isEqual);
// 使用 fill() 方法将整型数组的所有元素设置为 0int[] zeros = new int[5];Arrays.fill(zeros, 0);System.out.println(Arrays.toString(zeros));
// 使用 copyOf() 方法复制一个整型数组,并指定新数组的长度int[] original = {1, 2, 3};int[] copy = Arrays.copyOf(original, 5);System.out.println(Arrays.toString(copy));
// 使用 toString() 方法将整型数组转换为字符串形式String str = Arrays.toString(numbers);System.out.println(str);希望这些示例能够帮助您更好地了解如何使用 java.util.Arrays类中的方法。
Arrays.sort()方法可以用于对数组进行排序,支持升序和降序两种方式。但是,当数组中包含自定义类型的元素时,需要进行进阶使用。
对于自定义类型的元素,我们需要实现 Comparable接口,并重写其中的 compareTo()方法。这个方法定义了如何将一个元素与另一个元素进行比较。在 compareTo()方法中,我们需要返回一个整数值,表示当前元素与另一个元素的大小关系。如果当前元素小于另一个元素,则返回负整数;如果当前元素等于另一个元素,则返回 0;如果当前元素大于另一个元素,则返回正整数。
以下是一个自定义类型的示例代码:
public class Person implements Comparable<Person> { private String name; private int age;
public Person(String name, int age) { this.name = name; this.age = age; }
public String getName() { return name; }
public int getAge() { return age; }
@Override public int compareTo(Person o) { // 先按年龄排序,如果年龄相同则按姓名排序 if (this.age != o.age) { return this.age - o.age; } else { return this.name.compareTo(o.name); } }}在这个示例中,Person类实现了 Comparable接口,并重写了 compareTo()方法。在 compareTo()方法中,我们按照年龄和姓名的顺序进行比较。
使用 Arrays.sort()方法对包含自定义类型的数组进行排序时,只需要调用该方法即可。由于我们已经实现了 Comparable接口并重写了 compareTo()方法,因此 Java 会自动调用该方法来进行比较。
以下是一个使用 Arrays.sort()方法对包含自定义类型的数组进行排序的示例代码:
Person[] people = {new Person("Alice", 25), new Person("Bob", 20), new Person("Charlie", 30)};Arrays.sort(people);for (Person person : people) { System.out.println(person.getName() + " " + person.getAge());}在这个示例中,我们创建了一个包含三个 Person对象的数组,并调用 Arrays.sort()方法对其进行排序。由于我们已经实现了 Comparable接口并重写了 compareTo()方法,因此 Java 会按照指定的顺序进行排序。最后,我们使用循环打印排序后的结果。
System
Section titled “System”System 就是系统的意思。因此它的主要操作肯定也是和系统信息有关。这个类位于 java.lang 包。System 类内部的构造函数是私有的,在外部不能访问,因此不能被实例化了 功能:
- 系统信息的访问,如外部属性和环境变量等
- 垃圾回收相关操作
- 标准输入输出
- 比较常用的其他操作,比如数组拷贝
Method
Section titled “Method”System 类中提供了一些系统级的操作方法,常用的方法有 arraycopy()、currentTimeMillis()、exit()、gc()、getProperty()
arraycopy
Section titled “arraycopy”该方法的作用是数组复制,即从指定源数组中复制一个数组,复制从指定的位置开始,到目标数组的指定位置结束。该方法的具体定义如下:
/* * @param src the source array. * @param srcPos starting position in the source array. * @param dest the destination array. * @param destPos starting position in the destination data. * @param length the number of array elements to be copied.*/public static void arraycopy(Object src,int srcPos,Object dest,int destPos,int length)其中,src 表示源数组,srcPos 表示从源数组中复制的起始位置,dest 表示目标数组,destPos 表示要复制到的目标数组的起始位置,length 表示复制的个数。
currentTimeMillis
Section titled “currentTimeMillis”该方法的作用是返回当前的计算机时间,时间的格式为当前计算机时间与 GMT 时间(格林尼治时间)1970 年 1 月 1 日 0 时 0 分 0 秒所差的毫秒数。一般用它来测试程序的执行时间。例如:
long m = System.currentTimeMillis();该方法的作用是终止当前正在运行的 Java 虚拟机,具体的定义格式如下:
public static void exit(int status)其中,status 的值为 0时表示正常退出,非零时表示异常退出。使用该方法可以在图形界面编程中实现程序的退出功能等。
该方法的作用是请求系统进行垃圾回收,完成内存中的垃圾清除。至于系统是否立刻回收,取决于系统中垃圾回收算法的实现以及系统执行时的情况。定义如下:
public static void gc()getProperty
Section titled “getProperty”该方法的作用是获得系统中属性名为 key 的属性对应的值,具体的定义如下:
public static String getProperty(String key)系统中常见的属性名以及属性的说明如表 1 所示。
| 属性名 | 属性说明 |
|---|---|
| java.version | Java 运行时环境版本 |
| java.home | Java 安装目录 |
| os.name | 操作系统的名称 |
| os.version | 操作系统的版本 |
| user.name | 用户的账户名称 |
| user.home | 用户的主目录 |
| user.dir | 用户的当前工作目录 |
第一代日期类
java.util.Date
import java.text.SimpleDateFormat;import java.util.Date;
public class Main { public static void main(String[] args) throws ParseException { Date dNow = new Date(); //获取当前系统时间 Date d2 = new Date(99999); //通过指定毫秒数获取时间
SimpleDateFormat ft = new SimpleDateFormat("yyyy年MM月dd日 hh:mm:ss E"); String fmt = ft.format(dNow); System.out.println(fmt); //2023年08月29日 08:57:05 星期二
String s = "1996年1月1日 10:56:66 星期一"; Date parse = ft.parse(s); System.out.println(parse); }}java.util.Calendar
第二代日期类
- Calendar 是抽象类,构造器为 private
- 可以通过
getInstance()来获取实例
import java.util.Calendar;
public class Main { public static void main(String[] args) { System.out.println("世界你好!"); // 介绍Calendar的字段 Calendar c = Calendar.getInstance(); System.out.println(c); // 获取日历对象的某个日历字段 System.out.println("年: " + c.get(Calendar.YEAR)); System.out.println("月: " + (c.get(Calendar.MONTH) + 1)); System.out.println("日:" + c.get(Calendar.DAY_OF_MONTH)); System.out.println("小时: " + c.get(Calendar.HOUR)); //12h制 //Calendar.HOUR_OF_DAY System.out.println("分钟:" + c.get(Calendar.MINUTE)); System.out.println("秒: " + c.get(Calendar.SECOND)); // CaLender 没有专门的格式化方法,所以需要程序员自己来组合显示 System.out.println(c.get(Calendar.YEAR) + "年" + (c.get(Calendar.MONTH) + 1) + "月"); }}第三代日期类
第三代日期类是指 Java 8 中引入的新的日期和时间 API。该 API 包括一些新的类,例如 LocalDate、LocalTime 和 LocalDateTime,它们提供了更好的可读性和可维护性,并且比旧的 Date 和 Calendar 类更加安全。
这些类都有一些共同的 field 和 method,下面是一些常用的:
-
Field
- Year:年份,使用 4 位数字表示
- Month:月份,从 1 月开始到 12 月结束
- DayOfMonth:月份中的天数,从 1 开始到 31 结束
- DayOfWeek:星期几,从 Monday 开始到 Sunday 结束
- DayOfYear:年份中的天数,从 1 开始到 365 或 366 结束,取决于是否是闰年
- Hour:小时数,从 0 开始到 23 结束
- Minute:分钟数,从 0 开始到 59 结束
- Second:秒数,从 0 开始到 59 结束
- Nano:纳秒数,从 0 开始到 999,999,999 结束
-
Method
-
of():根据指定的年、月、日、时、分、秒等创建一个新的日期或时间对象
-
now():获取当前的日期或时间对象
-
plusXxx():在当前日期或时间上添加指定的年、月、日、时、分、秒等
-
minusXxx():在当前日期或时间上减去指定的年、月、日、时、分、秒等
LocalDateTime s = time1.plusDays(22); -
getXXX():获取指定的年、月、日、时、分、秒等
-
withXXX():设置指定的年、月、日、时、分、秒等为新的值
-
需要注意的是,这些类都是不可变的,因此它们的实例一旦创建就无法更改。如果需要修改日期或时间,则必须创建一个新的实例。此外,由于这些类不包含时区信息,因此在处理跨时区问题时需要格外小心。
import java.time.LocalDateTime;import java.time.format.DateTimeFormatter;
public class Main { public static void main(String[] args) { LocalDateTime date = LocalDateTime.now(); System.out.println(date); //格式化 DateTimeFormatter ofPattern = DateTimeFormatter.ofPattern("yyyy年MM月dd日 HH:mm:ss"); String fmt = ofPattern.format(date); System.out.println(fmt); }}//LocalDateTime 日期 + 时分秒//LocalDate 日期//LocalTime 时分秒时间戳 Instant
Instant instant = Instant.now();//Instant --> DateDate date = Date.from(instant);// Date --> InstantInstant instant = date.toInstant();集合框架体系
Section titled “集合框架体系”Iterator
Section titled “Iterator”Method
Section titled “Method”hasNext(); // Return true if the iteration has more elementsnext(); //remove();代码
import java.util.ArrayList;import java.util.Iterator;
public class Test { public static void main(String[] args) { ArrayList<Object> arrayList = new ArrayList<>(); arrayList.add("Hello"); arrayList.add("World"); arrayList.add(2); arrayList.add(new Object() { @Override public String toString() { return "I'm an object!"; } }); //迭代器遍历 Iterator iterator = arrayList.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } //增强for遍历,底层仍为迭代器,代码写起来更简便 for (Object object : arrayList) { System.out.println(object); } }}数组的不足之处
Section titled “数组的不足之处”- 长度开始时必须指定,且一旦指定不能修改
- 保存的必须为同一类型的数据
- 使用数组进行增加/删除元素比较麻烦
-
动态保存任意多个对象(基本数据类型会自动装箱为对象)
-
提供一系列方便的操作对象的方法
add move set get
-
使用集合增加/删除元素更方便
- 总结-开发中如何选择集合实现类在开发中,选择什么集合实现类,主要取决于业务操作特点,然后根据集合实现类特性进行选择,分析如下:
- 先判断存储的类型(一组对象[单列]或一组键值对[双列])
- 一组对象[单列]: Collection 接口
- 允许重复:
List- 增删多: LinkedList [底层维护了一个双向链表]
- 改查多: ArrayList [底层维护 Object 类型的可变数组
- 不允许重复:
Set- 无序: HashSet [底层是 HashMap ,维护了一个哈希表 即(数组+链表+红黑树)
- 排序: TreeSet
- 插入和取出顺序一致: LinkedHashSet,维护数组+双向链表 3)
- 允许重复:
- 一组键值对[双列]: Map
- 键无序: HashMap [底层是: 哈希表 jdk7: 数组+链表,jdk8: 数组+链表+红黑树]
- 键排序: TreeMap
- 键插入和取出顺序一致: LinkedHashMap
- 读取文件 Properties
Collection 接口的接口 对象的集合(单列集合) ├——-List 接口:元素按进入先后有序保存,可重复 │—————-├ LinkedList 接口实现类, 链表, 插入删除, 没有同步, 线程不安全 │—————-├ ArrayList 接口实现类, 数组, 随机访问, 没有同步, 线程不安全 │—————-└ Vector 接口实现类 数组, 同步, 线程安全 │ ———————-└ Stack 是 Vector 类的实现类 └——-Set 接口: 仅接收一次,不可重复,并做内部排序 ├—————-└
HashSet使用 hash 表(数组)存储元素 │————————└ LinkedHashSet链表维护元素的插入次序 └ —————-TreeSet 底层实现为二叉树,元素排好序└——-Queue 接口
└——-BeanContext 接口
Map 接口 键值对的集合 (双列集合) ├———Hashtable 接口实现类, 同步, 线程安全 ├———HashMap 接口实现类 ,没有同步, 线程不安全- │—————–├ LinkedHashMap 双向链表和哈希表实现 │—————–└ WeakHashMap ├ ——–TreeMap 红黑树对所有的 key 进行排序 └———IdentifyHashMap
从集合框架图可以看到,Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等
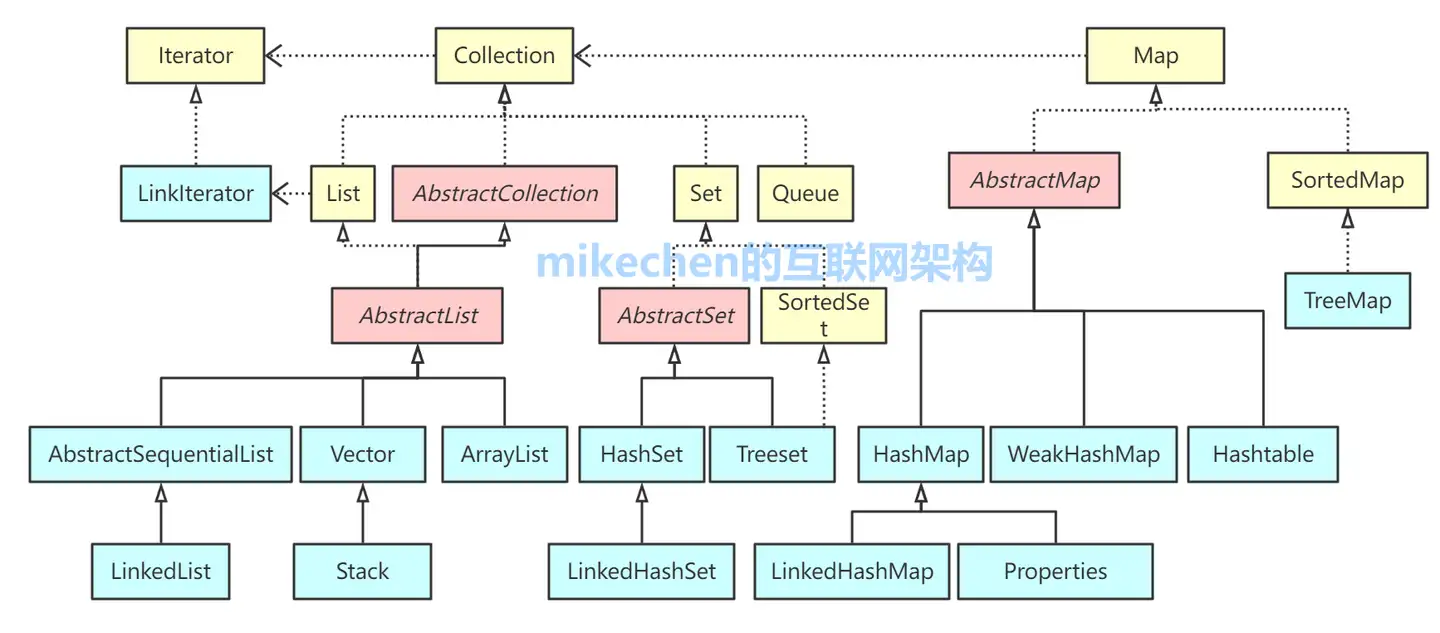
Collection
Section titled “Collection”Structure
Section titled “Structure”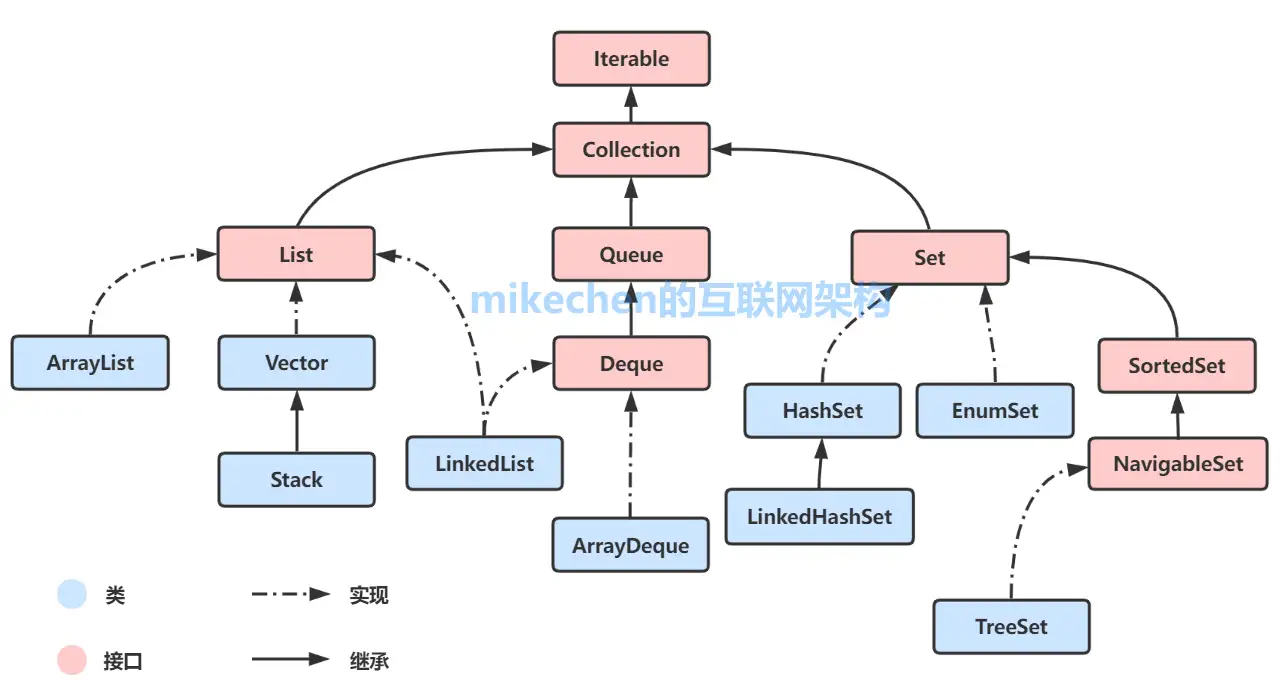
针对 Collection 集合我们到底使用谁呢?
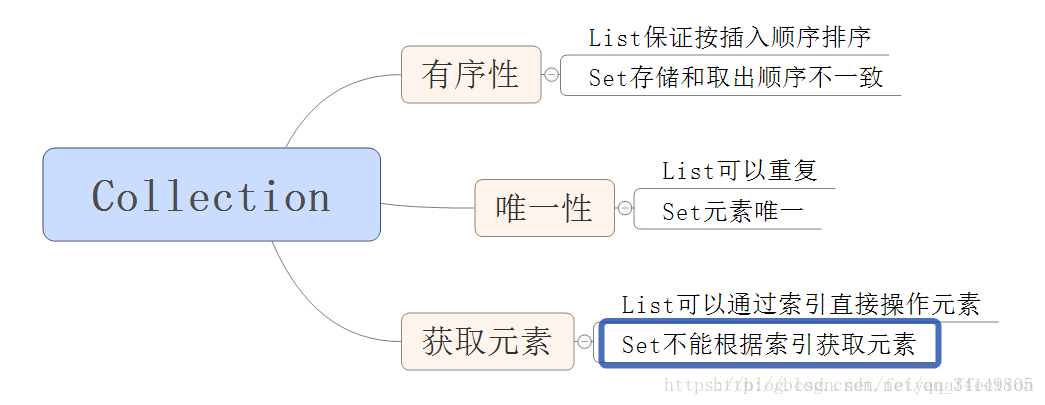
Collection Method
Section titled “Collection Method”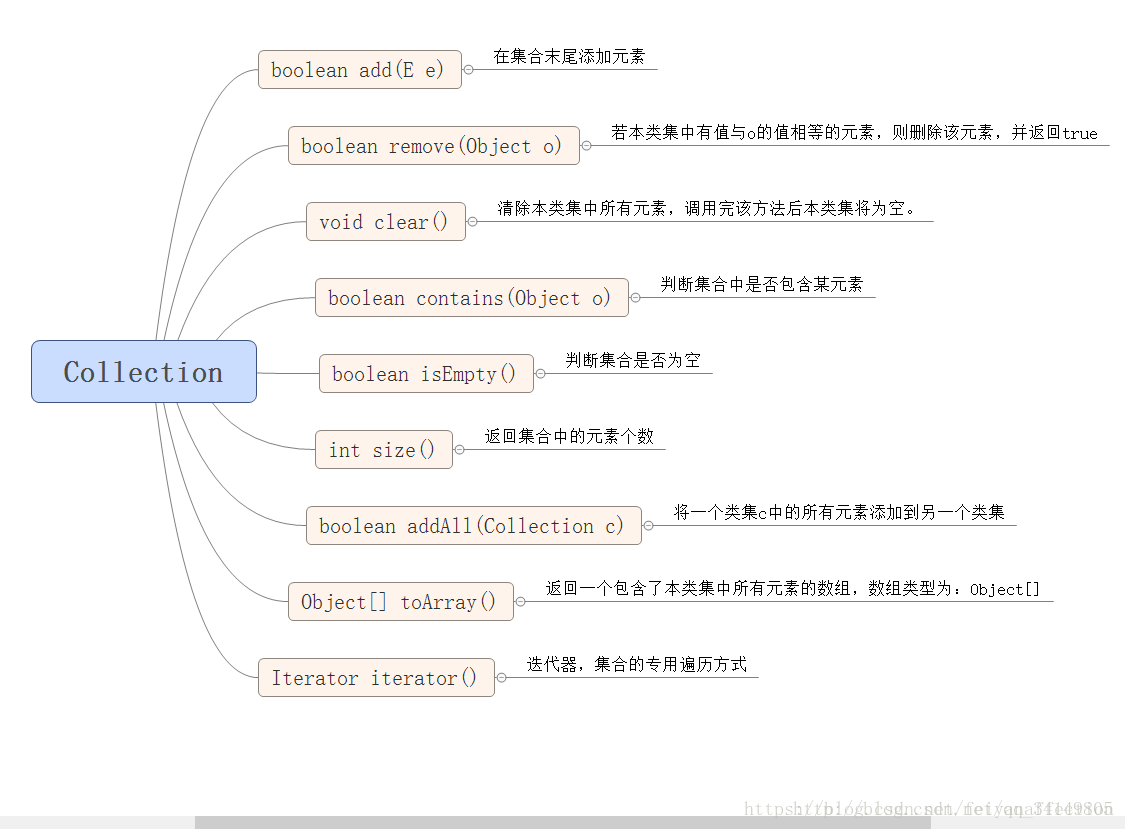
collection 集合中共性的方法,可以在 java.util.Collection 中查看,一共有如下 7 个,针对不同的实现类,都可以使用这 7 个方法。
public boolean add(E e):添加一个元素public void clear():清空集合中所有的元素public boolean remove(E e):移除集合中指定的元素public boolean contains(E e):检查集合中是否包含指定的对象public boolean isEmpty():判断集合是否为空public void size():判断集合中元素的个数public Object[] toArray():把集合元素存储到数组中- ArrayList:底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
- LinkedList 底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
- Vector:底层数据结构是数组,查询快,增删慢,线程安全,效率低,可以存储重复元素
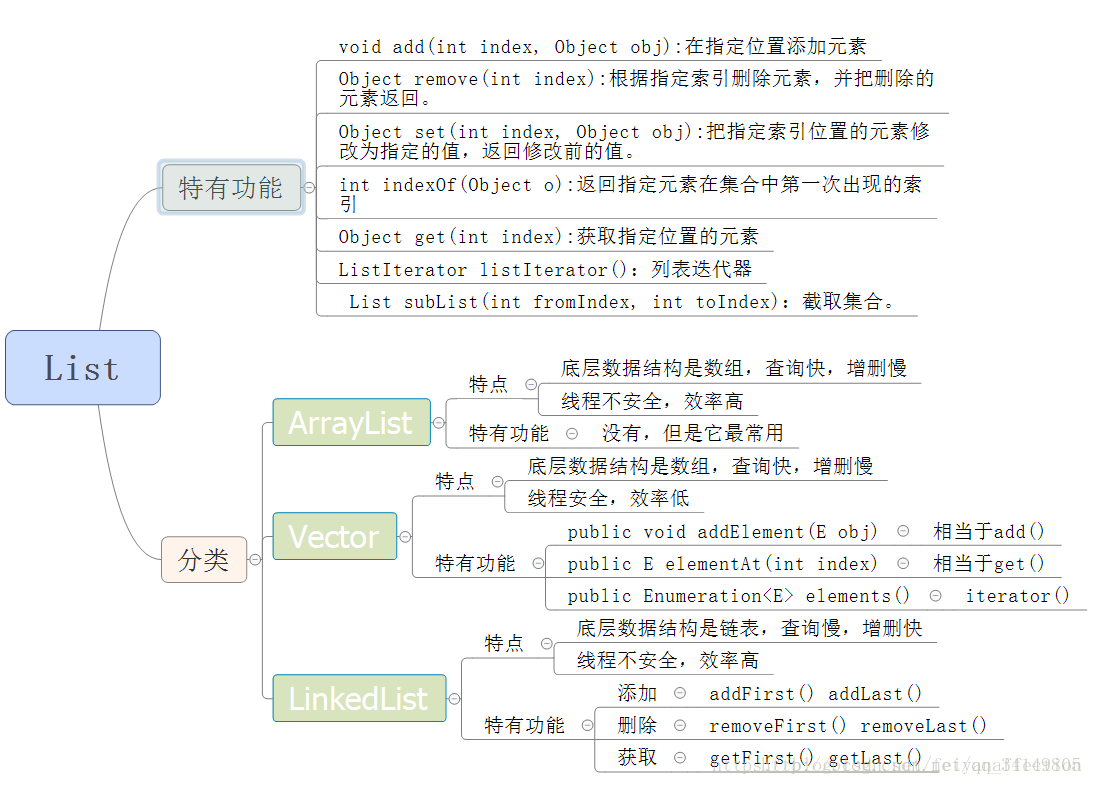
Method Of List Interface
Section titled “Method Of List Interface”add(Object o):在列表末尾添加元素。add(int index, Object o):在指定索引处添加元素。
ArrayList<String> list = new ArrayList<>();list.add("apple");list.add("banana");list.add(1, "orange");System.out.println(list); // 输出 [apple, orange, banana]remove(Object o):删除指定元素。remove(int index):删除指定索引处的元素。
ArrayList<String> list = new ArrayList<>();list.add("apple");list.add("banana");list.remove("banana");System.out.println(list); // 输出 [apple]
list.remove(0);System.out.println(list); // 输出 []contains(Object o):判断列表是否包含指定元素。
ArrayList<String> list = new ArrayList<>();list.add("apple");list.add("banana");boolean containsApple = list.contains("apple");System.out.println(containsApple); // 输出 trueindexOf(Object obj)lastIndexOf(Object obj)
ArrayList<String> list = new ArrayList<>(); list.add("apple"); list.add("banana"); list.add("apple"); int index = list.indexOf("apple"); // 输出0 int lastIndex = list.lastIndexOf("apple"); // 输出2get(int index):获取指定索引处的元素。
ArrayList<String> list = new ArrayList<>();list.add("apple");list.add("banana");String fruit = list.get(1);System.out.println(fruit); // 输出 bananaset(int index, Object obj)方法用于将列表中指定索引处的元素替换为指定的元素
List<String> list = new ArrayList<>();list.add("apple");list.add("banana");list.set(1, "orange");System.out.println(list); // 输出 [apple, orange]Others
Section titled “Others”subList(int fromIndex, int toIndex) 方法用于获取列表中指定范围内的子列表。
List<String> list = new ArrayList<>();list.add("apple");list.add("banana");list.add("orange");list.add("peach");List<String> subList = list.subList(1, 3);System.out.println(subList); // 输出 [banana, orange]需要注意的是,subList 方法返回的子列表是原列表的一个视图,对其进行修改会影响原列表。如果需要对子列表进行修改而不影响原列表,可以使用 ArrayList 的构造函数将其转换为一个新的列表。
List<String> list = new ArrayList<>();list.add("apple");list.add("banana");list.add("orange");list.add("peach");List<String> subList = list.subList(1, 3);List<String> newList = new ArrayList<>(subList);newList.set(1, "grape");System.out.println(list); // 输出 [apple, banana, orange, peach]System.out.println(subList); // 输出 [banana, orange]System.out.println(newList); // 输出 [banana, grape]ArrayList
Section titled “ArrayList”🚨Source Code
Section titled “🚨Source Code”-
ArrayList 中维护了一个 Object 类型的数组 elementData
transient Object[] elementData;transient表示瞬间短暂,表示该属性不会被序列化 -
当创建 ArrayList 对象时,如果使用的是无参构造器,则初始 elementData 容量为 0,第 1 次添加,则扩容 elementData 为 10,如需要再次扩容,则扩容 elementData 为 1.5 倍。
-
如果使用的是指定大小的构造器,则初始 elementData 容量为指定大小,如果需要扩容则直接扩容 elementData 为 1.5 倍
public ArrayList();public ArrayList(int initialCapacity);public ArrayList(Collection<? extends E>);无参构造器
第一次扩容为 10,之后的扩容将容量扩为当前的 1.5 倍
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};int DEFAULT_CAPACITY = 10;
public ArrayList() { this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; //创建一个空数组}
public boolean add(E e) { ensureCapacityInternal(size + 1); //确定是否需要扩容,size为数组长度,调用无参构造器初始时size = 0 elementData[size++] = e; return true;}
private void ensureCapacityInternal(int minCapacity) { // minCapacity = size + 1,初始为1; // 此处即为ensureExplictCapacity(10); ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));}
private static int calculateCapacity(Object[] elementData, int minCapacity) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { //elementData为空,返回DEFAULT_CAPACITY = 10 return Math.max(DEFAULT_CAPACITY, minCapacity); } return minCapacity;}
private void ensureExplicitCapacity(int minCapacity) { modCount++; //记录集合被修改的次数 //minCapacity = 10 if (minCapacity - elementData.length > 0) grow(minCapacity);//扩容}
private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; //oldCapacity = 0; int newCapacity = oldCapacity + (oldCapacity >> 1); //扩容1.5倍,初始时为0 if (newCapacity - minCapacity < 0) newCapacity = minCapacity;//newCapacity = 10 if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity);}LinkedList
Section titled “LinkedList”Array or Linked?
Section titled “Array or Linked?”实际开发中,业务需求多为改查,所以 Array 使用场景更多
以下情况使用 ArrayList :
- 频繁访问列表中的某一个元素(改查)。
以下情况使用 LinkedList :
- 需要频繁的在列表开头、中间、末尾等位置进行添加和删除元素操作。
LinkedList 类似于 ArrayList,是一种常用的数据容器。
public class LinkedList<E> { transient Node<E> first; transient Node<E> last;}
private static class Node<E> { E item; Node<E> next; Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev }}- 与 ArrayList 相比,LinkedList 的增加和删除的操作效率更高,而查找和修改的操作效率较低。
- LinkedList 底层维护了一个双向链表
- LinkedList 中维护了两个属性
first和last分别指向 首节点和尾节点 - 每个节点 (Node 对象),里面又维护了
prev、next、item三个属性,其中通过prev指向前一个,通过next指向后一个节点。最终实现双向链表. - 所以 LinkedList 的元素的添加和删除,不是通过数组完成的,相对来说效率较高
LinkedList的创建
// 引入 LinkedList 类import java.util.LinkedList;LinkedList<E> list = new LinkedList<E>(); // 普通创建方法LinkedList<E> list = new LinkedList(Collection<? extends E> c); // 使用集合创建链表LinkedList继承了 AbstractSequentialList 类。LinkedList实现了 Queue 接口,可作为队列使用。LinkedList实现了 List 接口,可进行列表的相关操作。LinkedList实现了 Deque 接口,可作为队列使用。LinkedList实现了 Cloneable 接口,可实现克隆。LinkedList实现了 java.io.Serializable 接口,即可支持序列化,能通过序列化去传输。
🚨Source Code
Section titled “🚨Source Code”void linkLast(E e) { final Node<E> l = last; //Node Constructor pre elem next; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; //modify_count}method
Section titled “method”LinkedList<Integer> linkedList = new LinkedList<Integer>();LinkedList<Integer> linkedList = new LinkedList<Integer>();for (int i = 0; i < 50; i++) { linkedList.add(i);}//method演示linkedList.remove(); //删除头结点,底层执行removeFirst()方法linkedList.removeLast();int i = linkedList.getFirst();int j = linkedList.getLast();linkedList.addFirst(1);linkedList.addLast(2);Vector
Section titled “Vector”底层结构可变数组
与 ArrayList类似基于数组实现,支持多线程访问,内部同步机制确保线程安全,也因此性能相比 ArrayList较差
protected Object[] elementData;扩容机制
- 如果是无参,默认 10 满后,就按 2 倍扩容
- 如果指定大小,则每次直接按 2 倍扩容
Set 基本介绍
Section titled “Set 基本介绍”- 实现
Set接口的对象,不能存放重复元素 - Set 接口为 Collection 的子接口,常用方法与 Collection 接口一样
- Set 接口存放数据是无序的,即添加顺序和取出的顺序不保证一致
- 取出顺序虽然与添加顺序不保证一致,但它是固定的
- Set 接口对象不能通过索引来获取
遍历
import java.util.`HashSet`;
import java.util.Iterator;
public class demo { public static void main(String[] args) { HashSet<Object> HashSet = new `HashSet`<>(); HashSet.add("a"); HashSet.add("b"); HashSet.add("c");
//Iterator Iterator iterator = HashSet.iterator(); while (iterator.hasNext()) { Object object = (Object) iterator.next(); System.out.println(object); } //增加for for (Object obj : HashSet) { System.out.println(obj); } //普通for,Error for (int i = 0; i < HashSet.size(); i++) { //不能通过索引访问 } }}HashSet
Section titled “HashSet”HashSet 底层数据结构采用哈希表实现,元素无序且唯一,线程不安全,效率高,可以存储 null 元素,元素的唯一性是靠所存储元素类型是否重写 hashCode()和 equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。 具体实现唯一性的比较过程:存储元素首先会使用 hash()算法函数生成一个 int 类型 hashCode 散列值,然后已经的所存储的元素的 hashCode 值比较,如果 hashCode 不相等,则所存储的两个对象一定不相等,此时存储当前的新的 hashCode 值处的元素对象;如果 hashCode 相等,存储元素的对象还是不一定相等,此时会调用 equals()方法判断两个对象的内容是否相等,如果内容相等,那么就是同一个对象,无需存储;如果比较的内容不相等,那么就是不同的对象,就该存储了,此时就要采用哈希的解决地址冲突算法,在当前 hashCode 值处类似一个新的链表, 在同一个 hashCode 值的后面存储存储不同的对象,这样就保证了元素的唯一性。 Set 的实现类的集合对象中不能够有重复元素,HashSet 也一样他是使用了一种标识来确定元素的不重复,HashSet 用一种算法来保证 HashSet 中的元素是不重复的, HashSet 采用哈希算法,底层用数组存储数据。默认初始化容量 16,加载因子 0.75。 Object 类中的 hashCode()的方法是所有子类都会继承这个方法,这个方法会用 Hash 算法算出一个 Hash(哈希)码值返回,HashSet 会用 Hash 码值去和数组长度取模, 模(这个模就是对象要存放在数组中的位置)相同时才会判断数组中的元素和要加入的对象的内容是否相同,如果不同才会添加进去。 Hash 算法是一种散列算法。
-
实现了 Set 接口
-
HashSet实际上是 HashMappublic HashSet() {map = new HashMap<>();} -
可以存放
null但只能存放一个null -
Set 接口存放数据是无序的,即添加顺序和取出的顺序不保证一致
-
HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是不确定的。 您必须在多线程访问时显式同步对 HashSet 的并发访问
-
取出顺序虽然与添加顺序不保证一致,但它是固定的
import java.util.HashSet;
class Person { String name; int age; public Person(String name, int age) { this.name = name; this.age = age; } @Override public String toString() { return "Person [name=" + name + ", age=" + age + "]"; }}
public class demo { public static void main(String[] args) { HashSet<Person> hashSet = new HashSet<Person>(); hashSet.add(new Person("张三", 20)); //true hashSet.add(new Person("张三", 20)); //true,两个Person并不是相同 for (Person person : hashSet) { System.out.println(person); } HashSet<String> hashSet2 = new HashSet<String>(); System.out.println(hashSet2.add(new String("张三"))); //true System.out.println(hashSet2.add(new String("张三"))); //fasle for (String string : hashSet2) { System.out.println(string); } }}Person [name=张三, age=20]Person [name=张三, age=20]truefalse张三🚨Source Code(Hash)
Section titled “🚨Source Code(Hash)”- HashSet 底层是 HashMap
- 添加一个元素时,先得到 hash 值(通过
hash(),hash 值不等于 hashCode(),因为,详见hash()) -会转成-> 索引值 - 找到存储数据表 table,看这个索引位置是否已经存放的有元素(数据表存放的是链表,在索引位置的链表查找元素)
- 如果没有,直接加入
- 如果有,调用 equals 比较,如果相同,就放弃添加,如果不相同,则添加到最后
- 在 Java8 中,如果一条链表的元素个数到达
TREEIFY THRESHOLD(默认是 8),并且 table 的大小 >=MIN TREEIFY CAPACITY(默认 64)就会进行树化(红黑树)
//序列化IDprivate static final long serialVersionUID = 362498820763181265L;//哈希表默认的桶数,也就是数组的长度,同时这个容量必须是二的次数幂 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 16//桶的最大数量static final int MAXIMUM_CAPACITY = 1 << 30; //2的30次方//默认的负载因子static final float DEFAULT_LOAD_FACTOR = 0.75f;//树化的阈值static final int TREEIFY_THRESHOLD = 8;//从树化变回链表的阈值static final int UNTREEIFY_THRESHOLD = 6;//树化的另一个控制参数,最小的桶数//所以树化:链表个数大于8,同时桶数不小于64static final int MIN_TREEIFY_CAPACITY = 64;//数组+链表中的数组transient Node<K,V>[] table;//threshold表示当HashMap的size大于threshold时会执行resize操作,就是扩容阈值int threshold;//当前key-value键值对个数transient int size;//结构修改时会自增,用于fast-fail机制transient int modCount;
//节点内部类,Node相关属性和方法static class Node<K,V> implements Map.Entry<K,V> { //Node的hash值 final int hash; //键值key final K key; //value值 V value; //链表的next节点 Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } public final K getKey() { return key; } public final V getValue() { return value; } public final String toString() { return key + "=" + value; } //计算hash值的算法,底层调用Object.hashCode()的native方法, //说明底层由cpp实现,这里就是返回key的哈希与value的哈希异或的值 public final int hashCode() { return Objects.hashCode(key) ^ Objects.hashCode(value); } //设置新值,并返回老值 public final V setValue(V newValue) { V oldValue = value; value = newValue; return oldValue; } //重写equals方法 public final boolean equals(Object o) { if (o == this) return true; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true; } return false; } }1.为什么桶的长度必须是 2 的整数次幂?
在后文中查找 hash 地址的时候,会进行取模运算,如果利用位运算进行取模运算必须保证长度为 2 的整数次幂 2.table 的默认值为 null,到底是什么时候初始化的?
使用懒加载机制,当第一次 put()时才会初始化,防止你 new 出来一个 HashMap 你不用,造成的内存浪费,在集合中懒加载机制十分常见 3.为什么要将链表树化?为什么又变回来?
当链表太长时,遍历又变成了链表的顺序查找,效率低下,变成红黑树可以加速查找速率,又变回来是因为链表长度缩短后,没必要使用红黑树,顺序查找足矣 4.什么是负载因子呢?
比如说当前的容器容量是 16,负载因子是 0.75,16*0.75=12,也就是说,当容量达到了 12 的时候就会进行扩容操作,也就是 resize()方法,负载因子是根据时间和空间权衡下经大量实验得到的,所以一般我们不传入负载因子
HashMap Constructor
Section titled “HashMap Constructor”- 双参构造器:指定 HashMap 的初始容量和负载因子
public HashMap(int initialCapacity, float loadFactor) { //检测initialCapacity和loadFactor的合法性 if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); //给负载因子赋值 this.loadFactor = loadFactor; //tableSizefor()方法稍后讲解 //这里就是根据传入的初始容量返回扩容阈值(必须是二的次数幂大小) this.threshold = tableSizeFor(initialCapacity); }- 指定初始容量创建 HashMap
//套娃,调用双参构造器,负载因子传入DEFAULT_LOAD_FACTOR默认负载因子public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); }- 空参构造器
public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted }//传入默认负载因子0.75,其他字段都是默认值- 集合构造器
public HashMap(Map<? extends K, ? extends V> m) { this.loadFactor = DEFAULT_LOAD_FACTOR; putMapEntries(m, false); }tableSizeFor()
Section titled “tableSizeFor()”tableSizeFor()方法,根据传入容量返回一个 >=cap的最小二的整数次幂的数
// |表示按位或运算// >>>无符号右移unsigned right shift,低位溢出,高位补0// 优先级 >>> 大于 |=static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }hash() & hashCode()
Section titled “hash() & hashCode()”// 执行HashSet()public HashSet() { map = new HashMap<>();}// 执行add()//If this set already contains the element, the call leaves the set unchanged and returns//PRESENT相当于Map中的Valuepublic boolean add(E e) { //E e: String java return map.put(e, PRESENT)==null;}//调用putVal()方法//传入的参数:经过哈希扰动和hashcode,key,val,onlyIfAbsent,evict//这里得到onlyIfAbsent表示如果hash冲突时,新值是否替换旧值,false表示替换public V put(K key, V value) { return putVal(hash(key), key, value, false, true);}
//hash(key)获得hash值,hash值 != hashCode(),因为进行了无符号右移16位static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value;
for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h;}putVal()
Section titled “putVal()”final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) { //tab表示当前的散列表 tab = table //p表示当前散列表的元素 //static class Node<K,V> {final int hash; final K key; V value; Node<K,V> mext;} //n表示散列表数组的长度tab.lenghh //i表示寻址的结果index Node<K,V>[] tab; Node<K,V> p; int n, i;// 定义辅助变量
🚨🚨🚨===============================PART I========================================= // 如果table表未初始化,或者数组长度为0,就会进行扩容操作,并返回扩容后的数组长度赋给n if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; //返回16
🚨🚨🚨===============================PART Ⅱ========================================= // ① i = (n-1) & hash = hash % n; // ② p = tab[i] // PS:(n-1)&hash是位运算符中的按位与运算符。它将哈希值hash与哈希表大小n-1进行按位与运算,得到一个索引i,用于在哈希表中定位节点。在这里,按位与运算符可以确保索引i在哈希表的范围内 // 计算i // 将p赋为tab[i]。这个值可能是一个节点,也可能是null // ①如果p为null,说明此处还没有存储元素,将key-value包装成Node设置在i处 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null);
🚨🚨🚨===============================PART Ⅲ=========================================; // ②如果p(即tab[i])不为null,则表示哈希表中已经存在一个节点,下面的代码来处理哈希冲突 else { //辅助变量,e用来记录冲突的结点,k表示当前所指向的结点的key,将k与插入结点的key比较 //如果相等,那么当前指向的结点即为冲突的结点,遍历结束没找到(e==null),则插入到尾部 Node<K,V> e; K k; ********** IF *********** // key可能是基本变量,也可能是引用变量(==比较基本数据类型的值,引用变量的地址;equals比较字符串的值) // key可能是对象,例如Person,Dog,此时equals的规则可以由程序员确定,在Person类中@Override即可 // 返回值为 k == key || (key != null && key.equals(k)); // 如果tab[i]的hash与要插入的结点的hash相等,并且tab[i]的key和要插入的key完全相同 // 则这里将p赋值给e,便于后文的替换操作 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; ************ ELSE-IF *********** //此时说明p已经树化,调用红黑树的方法添加到指定位置 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); ************ ELSE *********** //走到这里说明,hash寻址冲突了,并且和寻址结果i处的key不同,也不是树,说明此时要在链表上操作了 //遍历链表,直到找到一个空节点或者键相同的节点 /* 如果当前节点p不为空,则遍历p后面的链表,直到找到一个空节点或者键相同的节点。 * 在遍历链表的过程中,用变量binCount记录链表长度。 * 如果找到了一个空节点,则在该节点处插入新节点。 * 如果找到了键相同的节点,则跳出循环 */ else { for (int binCount = 0; ; ++binCount) { //binCount计算链表长度 //先让e = p.next,然后判断e是否为null //比较过程中,未找到key一样的结点,插入到尾部 if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); //如果链表长度达到了一个阈值,则将链表转化为树; if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } //发现了和要插入的节点完全一致的key,所以记录,跳出,后文替换 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } ************ FINAL *********** //替换操作,如果e!=null,说明e记录了冲突的节点 if (e != null) { // existing mapping for key V oldValue = e.value; //开头传入的参数flase,说明冲突时会进行替换操作 if (!onlyIfAbsent || oldValue == null) e.value = value; //具体实现在LinkedHashMap,此处不在详解 afterNodeAccess(e); return oldValue; } } 🚨🚨🚨===============================END========================================== ++modCount; //modifyCount对散列表操作进行记录,用于fast-fail机制 ////如果插入后元素超过了扩容阈值,就会进行扩容操作 if (++size > threshold) resize(); //HashMap的afterNodeInsertion为空,留给HashMap的子类实现;故此处执行空方法 //例如LinkedHashMap afterNodeInsertion(evict); return null; }懒加载机制
if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length;源码中我们可以看到,table 数组的初始化并不是在构造方法中,而是第一次调用 put()方法时,防止程序员 new 出来一个 HashMap 后并没有使用,所以在第一次 put()时才给占用内存较大的 table 申请空间
resize()
Section titled “resize()”final Node<K,V>[] resize() { //第一次扩容,大小为16个空间 /* * tab.resize() 是HashMap中的一个方法,用于调整哈希表的大小。 *当哈希表的负载因子(load factor)达到一定阈值时,tab.resize() 方法会被调用。 *它会创建一个更大的新哈希表,并将原有哈希表中的所有节点重新分配到新的哈希表中。借此提高HashMap的性能和效率,以适应不同负载情况下的数据存储需求 *具体的操作包括: ①创建一个新的哈希表,大小通常是当前哈希表大小的两倍;遍历原有哈希表中的每个节点。 ②根据节点的哈希值重新计算在新哈希表中的索引,并将节点插入到新哈希表的对应索引位置;将新哈希表替换为原有的哈希表 */ //引用扩容前的哈希表 Node<K,V>[] oldTab = table; //表示扩容前table数组的长度 int oldCap = (oldTab == null) ? 0 : oldTab.length; //表示扩容前的扩容阈值,触发本次扩容的阈值 int oldThr = threshold; //newCap:扩容之后table的大小 //newThr:下一次扩容的阈值 int newCap, newThr = 0;
//PART Ⅰ:确定newCap和newThr //如果oldCap>0,说明hashMap中的哈希表已经初始化了,这是一次正常的扩容 if (oldCap > 0) { //如果扩容之前table数组的大小已经达到了最大阈值后,就不再扩容,返回老数组,并设置阈值为最大容量 if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } //左移一位实现阈值翻倍并赋给新阈值,如果新阈值小于最大容量&&老阈值大于默认容量16,就把阈值翻倍 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } //oldCap == 0,表示table数组是null,还没有初始化,什么时候oldThr>0? //1.调用newHashMap(initCap,loadFactor) //2.调用newHashMap(initCap) //3.调用newHashMap(map) //这三种方法底层调用tableSizeFor()方法,返回threshold else if (oldThr > 0) // initial capacity was placed in threshold //所以初始化数组时,令threshold返回给newCap newCap = oldThr; else { // zero initial threshold signifies using defaults //此时oldCap==0, oldThr==0,说明调用的newHashMap()构造方法 //让新容量==默认值16 //新阈值为初始容量和初始负载因子的乘积 newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } //上面大部分逻辑是构造方法初始化的操作,如果已经初始化正常扩容 //就令newThr=newCap * loadFactor if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } //经过上述一系列操作后得到了新阈值 //得到新阈值后将其赋值给threshold threshold = newThr;
//PART Ⅱ:扩容 //如果旧表不为空,它将旧表中的所有元素复制到新表中,并根据它们的哈希码将它们放入新表中正确的位置 ///如果元素形成链,则需要在新表中维护相同的顺序。如果元素形成树,则需要拆分树并在新表中重新排列节点。 //以新容量为准,创建一个新数组 @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; //临时变量table table = newTab; //如果oldTab不为null,则开始遍历赋值到新数组的操作 if (oldTab != null) { //开始遍历所有数组的中的元素 for (int j = 0; j < oldCap; ++j) { //当前节点 Node<K,V> e; if ((e = oldTab[j]) != null) { //如果老数组原来位置的数据Node不为null,则将老数组i下标的Node置空,方便GC oldTab[j] = null; //第一种情况:桶位只有一个元素,没有发生过hash碰撞 if (e.next == null) //老方法计算出hash值,在新数组中复制这个元素 newTab[e.hash & (newCap - 1)] = e; //第二种情况:桶位已经树化 else if (e instanceof TreeNode) //调用树中的方法 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); //第三种情况:桶位链化,对链表的一些操作 else { //这里结合一张图理清,看下图 //走到这里希望你先把下面文章中的链表扩容操作看明白,接下来具体实施 //将链表分成了根据哈希值某一位分成高低两条链表,分别记录头尾节点 Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next; //循环插入 do { next = e.next; //分配到低位链表,插入到lo链表中 if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } //分配到高位链表,插入到高位链表中 else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); //上面的循环操作形成了两条链表,但还没有接到桶数组上 //将链表接到桶数组上 if (loTail != null) {//说明链表不为空 loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; //还是假设新容量是32 //因为生成了高低位两条链表,高位链表比低位链表多16位 //所以j+16表示高位链表的桶位,将高位链表和桶连接 newTab[j + oldCap] = hiHead; } } } } } //返回新桶 return newTab;}扩容对链表的复制操作,主要是:e.hash & oldCap用于链表截断分为高低位两条链表,具体实现如下:
- n 表示长度,是 2 的整数次幂,假设扩容前的 n=16,所以存放在 i=15 处的元素的寻址结果二进制为 i=1111,由于是与运算,所以hash值的最低四位为 1:xxxxxx1111,这样
hash&(n-1)结果才能是 i=1111

-
上文分析,在同一个桶位的 hash 值的后四位肯定是相同的,继续根据上文扩容后的 n=32,所以五个 bit 位决定桶位置,根据倒数第五位来将扩容前的长链表给分开,分为高低两条链表
假设倒数第五位是 1:xxxx11111,
e.hash & oldCap中 oldCap 是 16(二进制位):10000,所以结果:xxxx10000,存放到桶 16 的位置假设倒数第五位是 0: xxxx01111,
e.hash & oldCap中 oldCap 是 16(二进制位):10000,所以结果:xxxx00000,存放到桶 0 的位置这样高低两个链表存储位置差了一个 oldCap
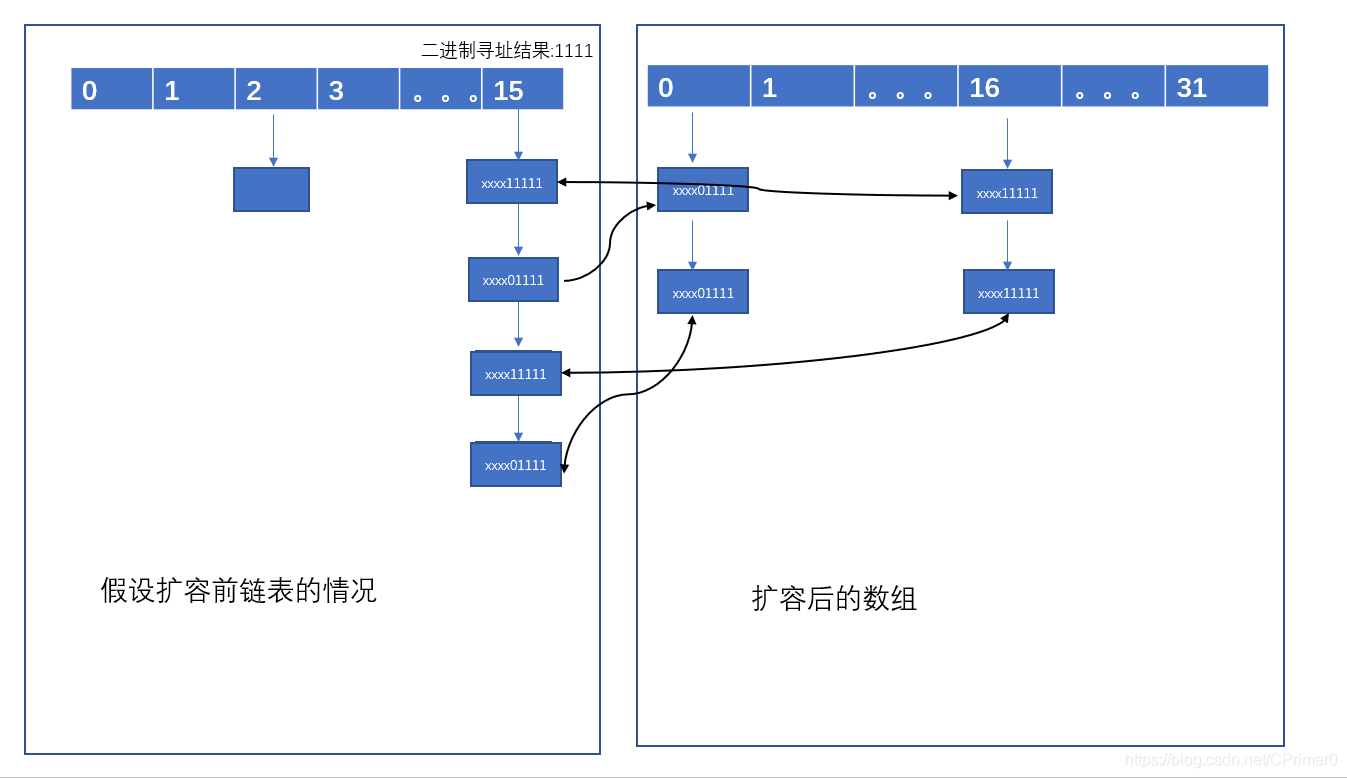
初始默认大小为 16,默认负载阈值 0.75,每次扩容 2 倍;
如果旧容量
oldCap>=MAXIMUM_CAPACITY最大容量 将扩容阈值 threshold 赋值尾Integer.MAX_VALUE,并不进行扩容操作,返回旧表如果 oldCap 以及 oldCap2 是介于 16 和最大容量之间,
oldCap * 2得到新容量,oldThr * 2得到新阈值如果
oldCap == 0 && oldThr > 0,那么 oldThr 直接赋给 newCapoldCap == 0,表示 table 数组是 null,还没有初始化,什么时候oldThr > 0?
调用
newHashMap(initCap,loadFactor)调用
newHashMap(initCap)调用
newHashMap(map)这三种构造方法底层调用
tableSizeFor()方法,返回 threshold 并赋值给了 oldThr一句话:在使用上述三种构造方法时,
newCap = oldThr如果
oldCap == 0 && oldThr == 0,那么将 16 赋给新容量,0.75*16 赋给新阈值 那什么时候oldThr == 0?
调用 newHashMap()空参构造器
一句话,使用空参构造器,
newCap=16,newThr=0.75*16上面是构造方法初始化的部分,如果已经初始化正常扩容,令
newThr=newCap * loadFactor确定了 newCap 和 newThr 后,正式进行扩容
- 如果桶位上没有元素,也就是没有 hash 冲突,直接设置新元素
- 如果桶位上冲突了,并且是冲突位置是树节点,就继续树相关操作
- 如果桶位上冲突了,不是树,说明就是普通的链表,就将链表拆分为高低两条链表存在新数组
newTab中
//调用getNode()方法,获取不到返回null,否则返回key对应的valuepublic V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; }final Node<K,V> getNode(int hash, Object key) { //临时变量,table数组, //first:桶也就是数组中索引对应的元素 //n:当前桶的长度 //K:对应的key值 Node<K,V>[] tab; Node<K,V> first, e; int n; K k; //如果table==null或者table的长度为0,说明table没初始化,或者长度为0,直接返回null //(n - 1) & hash寻址方式,如果寻址结果为null,直接返回null if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { //能进来说明table有数据,并且寻址结果找到的key不是null //判断:如果想要查询的key和寻址结果对应的key完全相同(包括hash,地址,equals判断) //找到了就直接返回 if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; //此时寻址结果不是想要答案,说明之前发生过哈希冲突,在对应的树或者链表上 if ((e = first.next) != null) { //在树上,进行树的相关查找 if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); //在链表上,从头节点到尾节点遍历查找 do { //找到了就返回 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } //找不到就返回null return null;}remove()
Section titled “remove()”//根据Key删除结点public V remove(Object key) { Node<K,V> e; return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value;}//根据key-value删除结点public boolean remove(Object key, Object value) { return removeNode(hash(key), key, value, true, true) != null;}
//matchValue:如果为true,表示key和value都对应上才删除//move参数暂时用不上,先不管final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { //临时变量依次用于存储桶,当前节点,桶长度,index索引 Node<K,V>[] tab; Node<K,V> p; int n, index; //如果table==null或者table的长度为0,说明table没初始化,或者长度为0,直接返回null //(n - 1) & hash熟悉的寻址方式,如果寻址结果为null,说明没找到,直接返回null if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { //能进来说明table有数据,并且寻址结果找到的key不是null Node<K,V> node = null, e; K k; V v; //判断:如果想要查询的key和寻址结果对应的key完全相同(包括hash,地址,equals判断) //如果找到key与传入的key相等的结点,利用临时变量node记录该结点 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p; //此时寻址结果不是想要答案,说明之前发生过哈希冲突,在对应的树或者链表上 else if ((e = p.next) != null) { //在树上,树的相关操作然后利用临时变量node传入key对应的节点 if (p instanceof TreeNode) node = ((TreeNode<K,V>)p).getTreeNode(hash, key); else { //说明在链表上 //循环找到key对应的节点,并且保存对应的node do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((e = e.next) != null); } } //如果node!=null,说明上面的流程找到了想要的node //matchValue判断是否key和value都要对应,如果要,就继续判断key对应的value是否相同 if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { //树的相关操作,移除掉node if (node instanceof TreeNode) ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); //如果是桶数组上的元素,直接令其==node.next else if (node == p) tab[index] = node.next; //链表删除node的操作 else p.next = node.next; //对链表结构改变的记录变量,用于fast-fail ++modCount; //删除一个元素--size --size; //根LinkedHashMap有关,本文暂不分析 afterNodeRemoval(node); //返回删除的节点 return node; } } //找不到返回null return null; }Method
Section titled “Method”//增删查改//定义Set<Integer> hashSet = new HashSet<Integer>();//增加hashSet.add(1);int[] nums = new int[]{1,2,3,4,5,6}for(int x : nums) hash.add(x);//删除hashSet.remove(1);hashSet.clear(); // 清空//查找hashSet.contains(1); //true//Others//计算大小hashSet.size();Exercise
Section titled “Exercise”Employee,重写 hashCode(),equals()
Section titled “Employee,重写 hashCode(),equals()”import java.util.Date;import java.util.HashSet;
class Employee { String name; int age; Date birthday; public Employee(String name, int age, Date birthday) { this.name = name; this.age = age; this.birthday = birthday; } @Override public String toString() { return "Employee [name=" + name + ", age=" + age + ", birthday=" + birthday + "]"; } @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + ((name == null) ? 0 : name.hashCode()); result = prime * result + age; result = prime * result + ((birthday == null) ? 0 : birthday.hashCode()); return result; } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Employee other = (Employee) obj; if (name == null) { if (other.name != null) return false; } else if (!name.equals(other.name)) return false; if (age != other.age) return false; if (birthday == null) { if (other.birthday != null) return false; } else if (!birthday.equals(other.birthday)) return false; return true; }
}
public class hashCode { public static void main(String[] args) { HashSet<Employee> employees = new HashSet<Employee>(); employees.add(new Employee("John", 30, new Date(1988-1-1))); employees.add(new Employee("John", 30, new Date(1988-1-1))); employees.add(new Employee("John", 30, new Date(1988-1-1))); System.out.println(employees); }}
输出[Employee [name=John, age=30, birthday=Thu Jan 01 08:00:01 CST 1970]]LinkedHashSet
Section titled “LinkedHashSet”-
LinkedHashSet是HashSet的子类 -
LinkedHashSet底层是一个LinkedHashMap,底层维护一个 数组 + 双向链表-
LinkedHashSet有 head 和 tail -
每一个结点有 pre 和 next 属性,这样可以形成双向链表
-
在添加一个元素时,先求 hash 值,再求索引,确定该元素在 hashtable 的位置,然后将添加的元素加入到双向链表(如果已经存在,不添加,原则与 hashset 一样)
tail.next = newElement;newElement.pro = tail;tail = newElement;
-
-
LinkedHashSet根据元素的 hashCode 值决定元素的存储位置,同时使用链表维护元素的次序,这使得元素看起来是以插入顺序保存的 -
LinkedHashSet不允许添加重复元素
🚨Source Code
Section titled “🚨Source Code”数组类型为 HashMap$Node[],存放的元素是 LinkedHashMap$Entry类型;体现数组的多态,Entry是 HashMap.Node的子类
HashMap.Node指 Node 是 HashMap 的静态内部类
//Entry static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } }static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; }
public final K getKey() { return key; } public final V getValue() { return value; } public final String toString() { return key + "=" + value; }
public final int hashCode() { return Objects.hashCode(key) ^ Objects.hashCode(value); }
public final V setValue(V newValue) { V oldValue = value; value = newValue; return oldValue; }
public final boolean equals(Object o) { if (o == this) return true; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true; } return false; }}Feature
Section titled “Feature”- Map 与 Collection 并列存在;用于保存具有映射关系的数据:Key-Value
- Map 中的 key 和 value 可以是任何引用类型的数据,会封装到
HashMap$Node对象中 - Map 中的 key 不允许重复,Map 中的 value 可以重复 Map 的 key 可以为 null, value 也可以为 null
- 注意 key 为 null,只能有一个;而 value 为 null ,可以多个.
- 常用 String 类作为 Map 的 key
- key 和 value 之间存在单向一对一关系,即通过指定的 key 总能找到对应的 value
- Map 存放数据的 key-value 示意图,一对 k-v 是放在一个 Node 中,Node 实现了 Entryjie’kou
Structure
Section titled “Structure”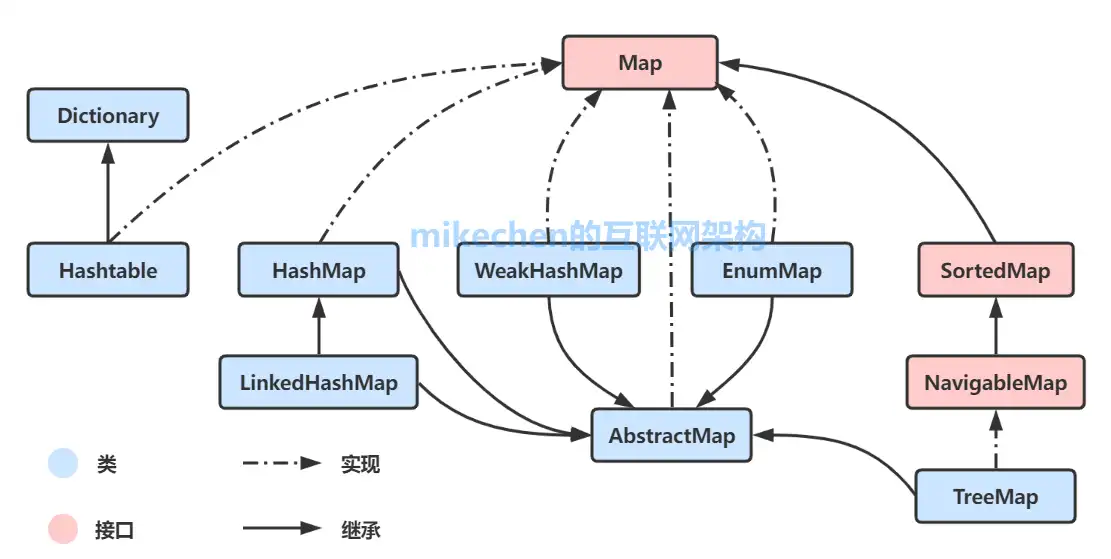
Map Method
Section titled “Map Method”Object put(Object key, Object value);//添加键值对,如果已经一个相同的Key则覆盖旧的键值对void putAll(Map m); //复制指定Map中的键值对到Map中Object remove(Object key);//删除指定key所对应的键值对,返回key所关联的value,如果key不存在则返回nullvoid clear(); //清空Mapint size(); //返回键值对的个数boolean containsValue(Object value); //查询Map中是否包含指定的value
import java.util.HashMap;import java.util.Iterator;
public class demo { public static void main(String[] args) { HashMap<String, String> hashMap = new HashMap<>(); hashMap.put("张三", "2022090902001"); hashMap.put("李四", "2022090902002"); hashMap.put("王五", "2022090902003"); hashMap.put("赵六", "2022090902004"); hashMap.put("孙七", "2022090902005"); // 遍历1,取出所有的key,通过key取出对应的value System.out.println("遍历1(1),取出所有的key,通过key取出对应的value"); for (String key : hashMap.keySet()) { System.out.println("key: " + key + " " + "value: " + hashMap.get(key)); } System.out.println("遍历1(2),key的迭代器"); Iterator<String> iterator = hashMap.keySet().iterator(); while (iterator.hasNext()) { String key = iterator.next(); System.out.println("key: " + key + "value: " + hashMap.get(key)); // 错误写法,iterator.next()调用一次就会向后移动一次 // System.out.println("key:" + iterator.next() + "value:" + // hashMap.get(iterator.next())); } // 遍历2,取出value,不能取出key System.out.println("遍历2(1),取出value增强for"); for (String value : hashMap.values()) { System.out.println("values:" + value); } System.out.println("遍历2(2),取出value iterator"); Iterator<String> iterator2 = hashMap.values().iterator(); while (iterator2.hasNext()) { System.out.println("values:" + iterator2.next()); } // 遍历3,EntrySet System.out.println("遍历3(1),取出EntrySet,增强for"); for (HashMap.Entry<String, String> entry : hashMap.entrySet()) { System.out.println("key:" + entry.getKey() + "value:" + entry.getValue()); } System.out.println("遍历3(2),取出EntrySet,iterator"); Iterator<HashMap.Entry<String, String>> iterator3 = hashMap.entrySet().iterator(); while (iterator3.hasNext()) { HashMap.Entry<String, String> entry = iterator3.next(); System.out.println("key:" + entry.getKey() + "value:" + entry.getValue()); } }}遍历1(1),取出所有的key,通过key取出对应的valuekey: 李四 value: 2022090902002key: 孙七 value: 2022090902005key: 张三 value: 2022090902001key: 王五 value: 2022090902003key: 赵六 value: 2022090902004遍历1(2),key的迭代器key: 李四value: 2022090902002key: 孙七value: 2022090902005key: 张三value: 2022090902001key: 王五value: 2022090902003key: 赵六value: 2022090902004遍历2(1),取出value增强forvalues:2022090902002values:2022090902005values:2022090902001values:2022090902003values:2022090902004遍历2(2),取出value iteratorvalues:2022090902002values:2022090902005values:2022090902001values:2022090902003values:2022090902004遍历3(1),取出EntrySet,增强forkey:李四value:2022090902002key:孙七value:2022090902005key:张三value:2022090902001key:王五value:2022090902003key:赵六value:2022090902004遍历3(2),取出EntrySet,iteratorkey:李四value:2022090902002key:孙七value:2022090902005key:张三value:2022090902001key:王五value:2022090902003key:赵六value:2022090902004
Hashmap
Section titled “Hashmap”Hashmap or Hashtable?
Section titled “Hashmap or Hashtable?”-
主要的不同点:
-
线程安全: HashMap 线程不安全 <—> HashTable 线程安全
-
实现方式: HashMap 用数组+链表+红黑树 <—> HashTable 用数组+链表
-
key 是否可为 null: HashMap 可以允许存在一个为 null 的 key 和任意个为 null 的 value <—> HashTable 中的 key 和 value 都不允许为 null
-
哈希不同,HashTable 直接使用对象的 hashCode。而 HashMap 重新计算 hash 值。
hashCode 是 jdk 根据对象的地址或者字符串或者数字算出来的 int 类型的数值。
Hashtable 计算 hash 值,直接用 key 的 hashCode(),而 HashMap 重新计算了 key 的 hash 值,Hashtable 在求 hash 值对应的位置索引时,用取模运算,而 HashMap 在求位置索引时,则用与运算,且这里一般先用 hash&0x7FFFFFFF 后,再对 length 取模,&0x7FFFFFFF 的目的是为了将负的 hash 值转化为正值,因为 hash 值有可能为负数,而 & 0x7FFFFFFF 后,只有符号外改变,而后面的位都不变。
-
HashTable 在不指定容量的情况下的默认容量为 11,而 HashMap 为 16,Hashtable 不要求底层数组的容量一定要为 2 的整数次幂,而 HashMap 则要求一定为 2 的整数次幂。 Hashtable 扩容时,将容量变为原来的 2 倍加 1,而 HashMap 扩容时,将容量变为原来的 2 倍。
Hashtable 和 HashMap 它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable 中 hash 数组默认大小是 11,增加的方式是 old*2+1。
-
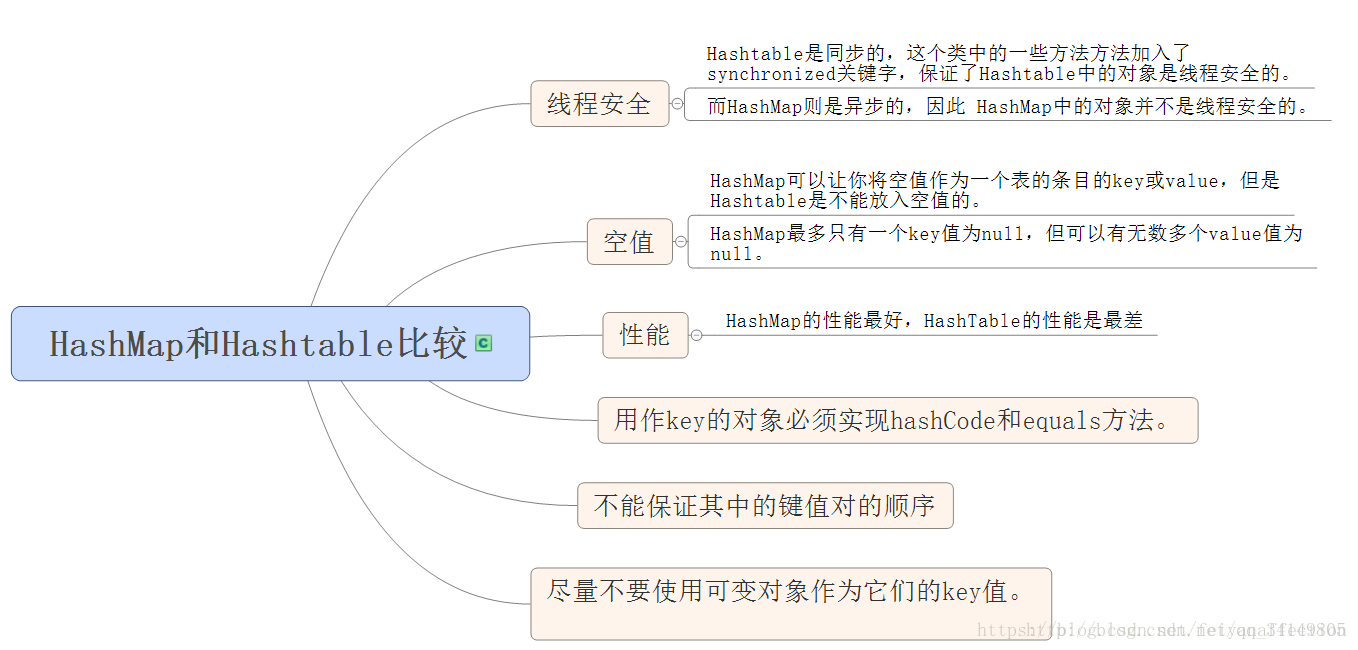
Source Code
Section titled “Source Code”- HashMap 底层维护了 Node 类型的数组 table,默认为 null
- 当创建对象时,将加载因子(loadfactor)初始化为 0.75.
- 当添加 key-val 时,通过 key 的哈希值得到在 table 的索引。然后判断该索引处是否有元素如果没有元素直接添加。如果该索引处有元素,继续判断该元素的 key 是否和准备加入的 key 相等,如果相等,则直接替换 val; 如果不相等需要判断是树结构还是链表结构,做出相应处理。如果添加时发现容量不够,则需要扩容。
- 第一次添加,则需要扩容 table 容量为 16,临界值(threshold)为 12
- 以后再扩容则需要扩容 table 容量为原来的 2 倍(32),临界值为原来的 2 倍,即 24,依次类推
- 在 Java8 中,如果一条链表的元素个数超过
TREEIFY THRESHOLD(default 8),并且table length >= MIN TREEIFY CAPACITY(默认 64),就会进行树化(红黑树)
- Map 接口的常用实现类: HashMap、Hashtable 和 Properties,HashMap 是 Map 接口使用频率最高的实现类。
- HashMap 是以 key-val 对的方式来存储数据(HashMap$Node 类型,Entry)
- key 不能重复,但是值可以重复,允许使用 null 键和 null 值.
- 如果添加相同的 key,则会覆盖原来的 key-val,等同于修改.(key 不会替换,val 会替换)
- 与 HashSet 一样,不保证映射的顺序,因为底层是以 hash 表的方式来存储的(jdk8 的 hashMap 底层 数组+链表+红黑树)
- HashMap 没有实现同步,因此是线程不安全的,方法没有做同步互斥的操作
Hashtable
Section titled “Hashtable”- 存放的元素是键值对: 即 K-V
- hashtable 的键和值都不能为 null,否则会抛出 NullPointerException
- hashTable 使用方法基本上和 HashMap 一样
- hashTable 是线程安全的(synchronized),hashMap 是线程不安全的
- ashtable 继承自 Dictionary,HashMap 继承自 AbstractMap
- 迭代器不同,Hashtable 是 enumerator 迭代器,HashMap 是 Iterator 迭代器
Properties
Section titled “Properties”Properties 继承于 Hashtable,用于管理配置信息的类。
由于 Properties 继承自 Hashtable 类,因此具有 Hashtable 的所有功能,同时还提供了一些特殊的方法来读取和写入属性文件。
Properties 类常用于存储程序的配置信息,例如数据库连接信息、日志输出配置、应用程序设置等。使用 Properties 类,可以将这些信息存储在一个文本文件中,并在程序中读取这些信息。
Properties 类被许多 Java 类使用。例如,在获取环境变量时它就作为 System.getProperties() 方法的返回值。
Properties 定义如下实例变量。这个变量持有一个 Properties 对象相关的默认属性列表。
Properties defaults;Properties 类定义了两个构造方法。 第一个构造方法没有默认值;Properties 类定义了两个构造方法。 第一个构造方法没有默认值
Properties();Properties(Properties propDefault);Method
Section titled “Method”| 号 | 方法描述 |
|---|---|
| 1 | String getProperty(String key) 用指定的键在此属性列表中搜索属性。 |
| 2 | String getProperty(String key, String defaultProperty) 用指定的键在属性列表中搜索属性。 |
| 3 | void list(PrintStream streamOut) 将属性列表输出到指定的输出流。 |
| 4 | void list(PrintWriter streamOut) 将属性列表输出到指定的输出流。 |
| 5 | void load(InputStream streamIn) throws IOException 从输入流中读取属性列表(键和元素对)。 |
| 6 | Enumeration propertyNames( ) 按简单的面向行的格式从输入字符流中读取属性列表(键和元素对)。 |
| 7 | Object setProperty(String key, String value) 调用 Hashtable 的方法 put。 |
| 8 | void store(OutputStream streamOut, String description) 以适合使用 load(InputStream)方法加载到 Properties 表中的格式,将此 Properties 表中的属性列表(键和元素对)写入输出流。 |
Properties prop = new Properties()- 增
prop.put("John",100);prop.setProperty("John",100); - 删
prop.remove("john"); - 查
prop.get(john);prop.getProperty("John") - 改
prop.put("john",500);//覆盖原先的值
- 增
Properties 类提供了多种读取和写入属性文件的方法。其中最常用的方法是 load() 和 store() 方法。
load() 方法可以从文件中读取属性,而 store() 方法可以将属性写入文件。
下面是一个简单的例子,演示了如何使用 Properties 类来读取和写入属性文件:
import java.io.*;import java.util.Properties;
public class PropertiesExample { public static void main(String[] args) { Properties prop = new Properties();
try { // 读取属性文件 prop.load(new FileInputStream("config.properties"));
// 获取属性值 String username = prop.getProperty("username"); String password = prop.getProperty("password");
// 输出属性值 System.out.println("username: " + username); System.out.println("password: " + password);
// 修改属性值 prop.setProperty("username", "newUsername"); prop.setProperty("password", "newPassword");
// 保存属性到文件 prop.store(new FileOutputStream("config.properties"), null);
} catch (IOException ex) { ex.printStackTrace(); } }}Tree Set & Tree Map
Section titled “Tree Set & Tree Map”TreeSet 基本介绍
Section titled “TreeSet 基本介绍”TreeSet 实现了 Set 接口,与 HashSet 不同的时,他是有序集合,底层是一个 TreeMap
默认按照升序排列,代码示例
TreeSet treeSet = new TreeSet();treeSet.add("tom");treeSet.add("lili");treeSet.add("kangkang");treeSet.add("abc");System.out.println(treeSet); // [abc, kangkang, lili, tom]自定义规则排序
TreeSet可以在初始化对象的时候传入一个接口对象,并对属性进行赋值
public TreeSet(Comparator<? super E> comparator) { this(new TreeMap<>(comparator));}
public TreeMap(Comparator<? super K> comparator) { this.comparator = comparator;}我们可以通过内部类的形式传入一个比较器,借助字符串的 compareTo方法对 TreeSet的排序进行自定义
例如,如下是一个升序排序:
TreeSet treeSet = new TreeSet(new Comparator() { @Override public int compare(Object o1, Object o2) { return ((String) o1).compareTo((String) o2); }});treeSet.add("tom");treeSet.add("lili");treeSet.add("kangkang");treeSet.add("abc");System.out.println(treeSet);自定义排序源码机制解读
Section titled “自定义排序源码机制解读”首先会进入 TreeSet的 add方法:
public boolean add(E e) { return m.put(e, PRESENT)==null;}之后,进入 TreeMap的 put方法:
public V put(K key, V value) { return put(key, value, true);}继续步入,直到添加了第二个元素,再次进入接受比较器的代码(核心):
Comparator<? super K> cpr = comparator;if (cpr != null) { do { parent = t; cmp = cpr.compare(key, t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else { V oldValue = t.value; if (replaceOld || oldValue == null) { t.value = value; } return oldValue; } } while (t != null);}注意:当我们传入比较器到 TreeSet中时,如果 TreeSet判断存在两个元素是相等的,则不会进行添加操作,怎么才算元素相等,取决于我们传入的比较器
例如:我们想实现一个功能,根据元素字符串的长度进行升序排序,那么我们可以这样编写比较器:
TreeSet treeSet1 = new TreeSet(new Comparator() { @Override public int compare(Object o1, Object o2) { return ((String) o1).length() - ((String) o2).length(); }});那么此时,元素的长度将会变成元素相等的条件,故我们执行如下代码块:
treeSet1.add("tom");treeSet1.add("lili");treeSet1.add("wangwei");treeSet1.add("wu");treeSet1.add("zhan");System.out.println(treeSet1); // [wu, tom, lili, wangwei]会发现,zhan元素并没有添加成功!
注意:对于
TreeMap的此种情况,他的 Key 值依然不会添加成功,但是会替换 value 的值
TreeMap 基本介绍
Section titled “TreeMap 基本介绍”TreeMap和 TreeSet差距不大,TreeMap保存键值对,默认按照键值升序排序
TreeMap treeMap = new TreeMap();treeMap.put("jack","杰克");treeMap.put("tom","汤姆");treeMap.put("smith","史密斯");System.out.println(treeMap); // {jack=杰克, smith=史密斯, tom=汤姆}TreeMap 的自定义排序
Section titled “TreeMap 的自定义排序”和 TreeSet一样,TreeMap也可以传入你个匿名内部类,实现自定义排序的效果
例如:按照 Key 值升序排序:
TreeMap treeMap = new TreeMap(new Comparator() { @Override public int compare(Object o, Object t1) { return ((String) o).compareTo((String) t1); }});treeMap.put("jack","杰克");treeMap.put("tom","汤姆");treeMap.put("smith","史密斯");System.out.println(treeMap);按照 Key 值逆序排序:
TreeMap treeMap = new TreeMap(new Comparator() { @Override public int compare(Object o, Object t1) { return ((String) t1).compareTo((String) o); }});treeMap.put("jack","杰克");treeMap.put("tom","汤姆");treeMap.put("smith","史密斯");System.out.println(treeMap);按照字符串长度从小到大排序:
TreeMap treeMap = new TreeMap(new Comparator() { @Override public int compare(Object o, Object t1) { return ((String) o).length() - ((String) t1).length(); }});treeMap.put("jack","杰克");treeMap.put("tom","汤姆");treeMap.put("smith","史密斯");System.out.println(treeMap);TreeMap与 TreeSet的源码大同小异
Collections
Section titled “Collections”常用 method
Section titled “常用 method”Collections类是 Java 中提供的一个工具类,它包含了许多常用的静态方法,用于操作集合对象。下面是几个常用的方法及其详细信息和示例:
-
sort(List<T> list)方法:对指定列表按升序排序。-
声明:
public static <T extends Comparable<? super T>> void sort(List<T> list) -
返回值:无
-
示例:
List<Integer> list = new ArrayList<>();list.add(3);list.add(1);list.add(2);Collections.sort(list);System.out.println(list); // [1, 2, 3]
-
-
reverse(List<?> list)方法:反转指定列表中元素的顺序。-
声明:
public static void reverse(List<?> list) -
返回值:无
-
示例:
List<String> list = new ArrayList<>();list.add("a");list.add("b");list.add("c");Collections.reverse(list);System.out.println(list); // [c, b, a]
-
-
shuffle(List<?> list)方法:随机重排指定列表中的元素。-
声明:
public static void shuffle(List<?> list) -
返回值:无
-
示例:
List<Integer> list = new ArrayList<>();for (int i = 1; i <= 10; i++) {list.add(i);}Collections.shuffle(list);System.out.println(list); // [7, 10, 3, 9, 5, 1, 4, 8, 6, 2]
-
-
binarySearch(List<? extends Comparable<? super T>> list, T key)方法:在指定列表中使用二分查找算法查找指定元素。-
声明:
public static <T> int binarySearch(List<? extends Comparable<? super T>> list, T key) -
返回值:如果找到指定元素,则返回其索引;否则返回一个负数。
-
示例:
List<Integer> list = new ArrayList<>();for (int i = 1; i <= 10; i++) {list.add(i);}int index = Collections.binarySearch(list, 5);System.out.println(index); // 4
-
-
max(Collection<? extends T> coll)方法:返回指定集合中的最大元素。-
声明:
public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll) -
返回值:集合中的最大元素。
-
示例:
List<Integer> list = new ArrayList<>();list.add(3);list.add(1);list.add(2);int max = Collections.max(list);System.out.println(max); // 3
-
-
swap(List<?> list, int i, int j)方法:交换指定列表中指定位置的两个元素。-
声明:public static void swap(List<?> list, int i, int j)
-
返回值:无
-
示例:
List<String> list = new ArrayList<>();list.add("a");list.add("b");list.add("c");System.out.println(list); // [a, b, c]Collections.swap(list, 0, 2);System.out.println(list); // [c, b, a]以上是Collections类中的一些常用方法。这些方法提供了方便的方式来操作和处理集合对象。
-
-
-
copy(List<? super T> dest, List<? extends T> src)方法:将源列表中的所有元素复制到目标列表中。- 声明:
public static <T> void copy(List<? super T> dest, List<? extends T> src) - 返回值:无
- 示例:
List<String> src = new ArrayList<>();src.add("a");src.add("b");src.add("c");List<String> dest = new ArrayList<>(Arrays.asList(new String[src.size()]));Collections.copy(dest, src);System.out.println(dest); // [a, b, c] - 声明:
-
frequency(Collection<?> c, Object o)方法:返回指定集合中等于指定对象的元素的数量。- 声明:
public static int frequency(Collection<?> c, Object o) - 返回值:指定集合中等于指定对象的元素的数量
- 示例:
List<Integer> list = new ArrayList<>();list.add(1);list.add(2);list.add(3);list.add(1);int frequency = Collections.frequency(list, 1);System.out.println(frequency); // 2 - 声明:
以上是 Collections类中的常用方法,这些方法可以方便地处理和操作集合对象。
非常抱歉,我对之前的回答有所疏漏。以下是 Collections类中的其他常用方法及其详细信息和示例:
-
replaceAll(List<T> list, T oldVal, T newVal)方法:将指定列表中所有等于旧值的元素替换为新值。-
声明:
public static <T> boolean replaceAll(List<T> list, T oldVal, T newVal) -
返回值:如果列表中包含旧值,则返回
true,否则返回false -
示例:
List<String> list = new ArrayList<>();list.add("a");list.add("b");list.add("c");list.add("a");boolean replaced = Collections.replaceAll(list, "a", "d");System.out.println(list); // [d, b, c, d]System.out.println(replaced); // true
-
-
min(Collection<? extends T> coll)方法:返回指定集合中的最小元素。-
声明:
public static <T extends Object & Comparable<? super T>> T min(Collection<? extends T> coll) -
返回值:指定集合中的最小元素
-
示例:
List<Integer> list = new ArrayList<>();list.add(3);list.add(1);list.add(2);Integer min = Collections.min(list);System.out.println(min); // 1
-
-
fill(List<? super T> list, T obj)方法:用指定的元素替换指定列表中的所有元素。-
声明:
public static <T> void fill(List<? super T> list, T obj) -
返回值:无
-
示例:
List<String> list = new ArrayList<>();list.add("a");list.add("b");list.add("c");Collections.fill(list, "d");System.out.println(list); // [d, d, d]
-
试分析 HashSet 和 TreeSet 分别如何实现去重的
Section titled “试分析 HashSet 和 TreeSet 分别如何实现去重的”- HashSet 的去重机制:
hashCode() + equals(),底层先通过存入对象,进行运算得到一个 hash 值,通过 hash 值得到对应的索引,如果发现 table 索引所在的位置,没有数据,就直接存放如果有数据,就进行 equals 比较,如果比较后,不相同,就加入,否则就不加入 - TreeSet 的去重机制: 如果你传入了一个 Comparator 匿名对象,就使用实现的 compare 去重,如果方法返回 0,就认为是相同的元素/数据,就不添加,如果你没有传入一个 Comparator 匿名对象,则以你添加的对象实现的 Compareable 接口的 compareTo 去重
ArrayList 与 Vector 的区别
Section titled “ArrayList 与 Vector 的区别”| 底层结构 | 版本 | 线程安全&效率 | 扩容倍数 | |
|---|---|---|---|---|
ArrayList | 可变数组 | jdk1.2 | 不安全,效率高 | 如果使用有参构造器,按照 1.5 倍扩容,如果是无参构造器,第一次扩容 10,从第二次开始按照 1.5 倍扩容 |
Vector | 可变数组 Object[] | jdk1.0 | 安全,效率低 | 如果使用有参构造器,按照 2 倍扩容,如果是无参构造器,第一次扩容 10,从第二次开始按照 2 倍扩容 |
分析输出
import java.util.HashSet;
public class hashSetTest { public static void main(String[] args) { HashSet<Object> hashSet = new HashSet<>(); Person person1 = new Person("AA", 1001); Person person2 = new Person("BB", 1002); hashSet.add(person1); // ok hashSet.add(person2); // ok System.out.println(hashSet); person1.name = "CC";//person1的Index由AA,1001计算的Hash值确定 hashSet.remove(person1); // 删除失败,因为person1的hash值已经改变;原先的hash值为AA,1001计算得来,现在为CC,1001 System.out.println(hashSet); hashSet.add(new Person("CC", 1001)); // 添加成功,他的hashCode与person1的一样,但Index不一样 System.out.println(hashSet); hashSet.add(new Person("AA", 1001)); // 添加成功,他的index与person1一样,但与person1的hashCode不同 System.out.println(hashSet); }}
class Person { public String name; public int id;
public Person(String name, int id) { this.name = name; this.id = id; }
@Override public String toString() { return "Person [name=" + name + ", id=" + id + "]"; }
@Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + ((name == null) ? 0 : name.hashCode()); result = prime * result + id; return result; }
@Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Person other = (Person) obj; if (name == null) { if (other.name != null) return false; } else if (!name.equals(other.name)) return false; if (id != other.id) return false; return true; }
}[Person [name=BB, id=1002], Person [name=AA, id=1001]][Person [name=BB, id=1002], Person [name=CC, id=1001]][Person [name=BB, id=1002], Person [name=CC, id=1001], Person [name=CC, id=1001]][Person [name=BB, id=1002], Person [name=CC, id=1001], Person [name=CC, id=1001], Person [name=AA, id=1001]]